
考慮到目前市場上Alexa、Google Assistant、DuerOS、AliGenie等語音智能平臺都有各自的優缺點,本文講述的語音交互設計將是通用、抽象型的,以及不會針對任意一款語音智能平臺進行設計。enjoy~

對話是人與人之間交換信息的普遍方式。人可以在交流時通過判別對方的語氣、眼神和表情判斷對方表達的情感,以及根據自身的語言、文化、經驗和能力理解對方所發出的信息,但對于只有0(false)和1(true)的計算機來講,理解人的對話是一件非常困難的事情,因為計算機不具備以上能力,所以目前的語音交互主要由人來設計。
有人覺得語音交互設計就是設計怎么問怎么答,看似很簡單也很無聊,但其實語音交互設計涉及系統學、語言學和心理學,因此它比GUI的交互設計復雜很多。
要做好一個好的語音交互設計,需要知道:
- 第一,自己的產品主要服務對象是誰?單人還是多人使用?
- 第二,要對你即將使用的語音智能平臺非常了解;
- 第三是考慮清楚你設計的產品使用在哪,純語音音箱還是帶屏幕的語音設備?
了解完以上三點你才能更好地去設計一款語音產品。
考慮到目前市場上Alexa、Google Assistant、DuerOS、AliGenie等語音智能平臺都有各自的優缺點,以下講述的語音交互設計將是通用、抽象型的,以及不會針對任意一款語音智能平臺進行設計。
語音交互相關術語
在設計語言交互之前,我們先了解一下與語音交互相關的術語:
技能(Skill)
技能可以簡單理解為一個應用。當用戶說“Alexa,我要看新聞”或者說“Alexa,我要在京東上買東西”時,用戶將分別打開新聞技能和京東購物兩項技能,而“新聞”和“京東”兩個詞都屬于觸發該技能的關鍵詞,也就是打開該應用的入口,后面用戶說的話都會優先匹配該項技能里面的意圖。由于用戶呼喊觸發詞會加深用戶對該品牌的記憶,因此觸發詞具有很高的商業價值。
“Alexa”是喚醒語音設備的喚醒詞,相當于手機的解鎖頁面,同時也是便捷回到首頁的home鍵。目前的語音設備需要被喚醒才能執行相關操作,例如“Alexa,現在幾點?”、“Alexa,幫我設置一個鬧鐘”。這樣設計的好處是省電以及保護用戶隱私,避免設備長時間錄音。
意圖(Intent)
意圖可以簡單理解為某個應用的功能或者流程,主要滿足用戶的請求或目的。意圖是多句表達形式的集合,例如“我要看電影”和“我想看2001年劉德華拍攝的動作電影”都可以屬于同一個視頻播放的意圖。意圖要隸屬于某項技能,例如“京東,我要買巧克力”這個案例,“我要買巧克力”這個意圖是屬于京東這個技能的。當用戶說“Alexa,我要買巧克力”,如果系統不知道這項意圖屬于哪個技能時,系統是無法理解并且執行的。
但是,有些意圖不一定依賴于技能,例如“Alexa,今天深圳天氣怎么樣”這種意圖就可以忽略技能而直接執行,因為它們默認屬于系統技能。當語音設備上存在第三方天氣技能時,如果用戶直接喊“Alexa,今天深圳天氣怎么樣”,系統還是會直接執行默認的意圖。我們做語音交互更多是在設計意圖,也就是設計意圖要怎么理解以及執行相關操作。
詞典(Dictionary)
詞典可以理解為某個領域內詞匯的集合,是用戶與技能交互過程中的一個重要概念。例如“北京”、“廣州”、“深圳”都屬于“中國城市”這項詞典,同時屬于“地點”這項范圍更大的詞典;“下雨”、“臺風”、“天晴”都屬于“天氣”這項詞典。有些詞語會存在于不同詞典中,不同詞典的調用也會影響意圖的識別。例如“劉德華”、“張學友”、“陳奕迅”都屬于“男歌星”這項詞典,同時他們也屬于“電影男演員”這項詞典。
當用戶說“我要看劉德華電影”的時候,系統更多是匹配到電影男演員的“劉德華”;如果用戶說“我想聽劉德華的歌”,系統更多是匹配到男歌星詞典里的“劉德華”。如果用戶說出“打開劉德華”模棱兩可的話術時,那么這句話究竟是匹配視頻意圖還是歌曲意圖呢?這時候就需要人為設計相關的策略來匹配意圖。
詞槽(Slot)
詞槽可以理解為一句話中所包含的參數是什么,而槽位是指這句話里有多少個參數,它們直接決定系統能否匹配到正確的意圖。舉個例子,“今天深圳天氣怎么樣”這項天氣意圖可以拆分成“今天”、“深圳”、“天氣”、“怎么樣”四個詞語,那么天氣意圖就包含了“時間”、“地點”、“觸發關鍵詞”、“無義詞”四個詞槽。
詞槽和詞典是有強關系的,同時詞槽和槽位跟語言的語法也是強相關的。例如“聲音大一點”這句話里就包括了主語、謂語和狀語,如果缺乏主語,那么語音智能平臺是不知道哪個東西該“大一點”。在設計前,我們要先了解清楚語音智能平臺是否支持詞槽狀態選擇(可選、必選)、是否具備泛化能力以及槽位是否支持通配符。詞槽和槽位是設計意圖中最重要的環節,它們能直接影響你未來的工作量。
泛化(Generalize)
一個語音智能平臺的泛化能力能直接影響系統能否聽懂用戶在說什么以及設計師的工作量大小,同時也能反映出該平臺的人工智能水平到底怎么樣。究竟什么是泛化?泛化是指同一個意圖有不同表達方式,例如“聲音幫我大一點”、“聲音大一點”、“聲音再大一點點”都屬于調節音量的意圖,但是表達的差異可能會直接導致槽位的設計失效,從而無法識別出這句話究竟是什么意思。
目前所有語音智能平臺的泛化能力相當較弱,需要設計師源源不斷地將不同的表達方式寫入系統里。詞槽和槽位的設計也會影響泛化能力,如果設計不當,設計人員的工作可能會翻好幾倍。
通配符(Wildcard Character)
通配符主要用來進行模糊搜索和匹配。當用戶查找文字時不知道真正的字符或者懶得輸入完整名字時,常常使用通配符來代替字符。通配符在意圖設計中非常有用,尤其是數據缺乏導致某些詞典數據不全的時候,它能直接簡化制作詞典的工作量。例如“XXX”為一個通配符,當我為“視頻播放”這項意圖增加“我想看XXX電影”這項表達后,無論XXX是什么,只要系統命中“看”和“電影”兩個關鍵詞,系統都能打開視頻應用搜索XXX的電影。
但是,通配符對語音交互來說其實是一把雙刃劍。
假設我們設計了一個“打開XXX”的意圖,當用戶說“打開電燈”其實是要開啟物聯網中的電燈設備,而“打開哈利波特”是要觀看哈利波特的系列電影或者小說。當我們設計一個“我要看XXX”和“我要看XXX電影”兩個意圖時,很明顯前者包含了后者。通配符用得越多會影響詞槽和槽位的設計,導致系統識別意圖時不知道如何對眾多符合的意圖進行排序,所以通配符一定要合理使用。
自動語音識別技術(ASR,Automatic Speech Recognition)
將語音直接轉換成文字,有些時候由于語句里某些詞可能聽不清楚或者出現二異性會導致文字出錯。
語音智能平臺如何聽懂用戶說的話
語音交互主要分為兩部分,第一部分是“聽懂”,第二部分才是與人進行交互。如果連用戶說的是什么都聽不懂,那么就不用考慮后面的流程了。這就好比如打開的所有網頁鏈接全是404一樣,用戶使用你的產品會經常感受到挫敗感。因此能否“聽懂”用戶說的話是最能體現語音產品人工智能能力的前提。
決定你的產品是否能聽懂用戶說的大部分內容,主要由語音智能平臺決定,我們在做產品設計前需要先了解清楚語音智能平臺的以下七個方面:
1. 當前使用的語音智能平臺NLU(Natural Language Understanding,自然語言理解)能力如何,尤其是否具備較好的泛化能力。NLU是每個語音智能平臺的核心。
2. 了解系統的意圖匹配規則是完全匹配還是模糊匹配?以聲音調整作為例子。假設聲音調整這個意圖由“操作對象”、“調整”和“狀態”三個詞槽決定,“聲音提高一點”這句話里的“聲音”、“提高”和“一點”分別對應“操作對象”、“調整”和“狀態”三個詞槽。如果這時候用戶說“請幫我聲音提高一點”,這時候因為增加了“請幫我”三個字導致意圖匹配不了,那么該系統的意圖匹配規則是完全匹配,如果能匹配成功說明意圖匹配規則支持模糊匹配。
只支持詞槽完全匹配的語音智能平臺幾乎沒有任何泛化能力,這時候設計師需要考慮通過構建詞典、詞槽和槽位的方式實現意圖泛化,這非常考驗設計師的語言理解水平、邏輯能力以及對整體詞典、詞槽、槽位的全局設計能力,我們可以認為這項任務極其艱巨。
如果語音智能平臺支持詞槽模糊匹配,說明系統采用了識別關鍵詞的做法,以剛剛的“請幫我聲音提高一點”作為例子,系統能識別出“聲音提高一點”分別屬于“操作對象”、“調整”和“狀態”三個詞槽,然后匹配對應的意圖,而其他文字“請幫我”或者“請幫幫我吧”將會被忽略。模糊匹配能力對意圖的泛化能力有明顯的提升,能極大減少設計師的工作量,因為我們盡可能選擇具備模糊匹配能力的語音智能平臺。
3. 當前使用的語音智能平臺對語言的支持程度如何。每種語言都有自己的語法和特點,這導致了目前的NLU不能很好地支持各種語言,例如Alexa、Google Assistant和Siri都在深耕英語英文的識別和理解,但對漢語中文的理解會相對差很多,而國內的DuerOS、AliGenie等語音智能平臺則相反。
4. 有些詞典我們很難通過手動的方式收集完整,例如具有時效性的名人詞典還有熱詞詞典。如果收集不完整最終結果就是系統很有可能不知道你說的語句是什么意思。這時候我們需要官方提供的系統詞典,它能直接幫助我們減輕大量的工作。系統詞典一般是對一些通用領域的詞匯進行整理的詞典,例如城市詞典、計量單位詞典、數字詞典、名人詞典還有音樂詞典等等。因此我們需要了解當前使用的語音智能平臺的系統詞典數量是否夠多,每個詞典擁有的詞匯量是否齊全。
5. 了解清楚語音智能平臺是否支持客戶端和服務端自定義參數的傳輸,這一項非常重要,尤其是對帶屏幕的語音設備來說。我們做設計最注重的是用戶在哪個場景下做了什么,簡單點就是5W1H,What(什么事情)、Where(什么地點)、When(什么時候)、Who(用戶是誰)、Why(原因)和How(如何),這些都可以理解為場景化的多個參數。
據我了解,有些語音智能平臺在將語音轉換為文字時是不支傳輸傳自定義參數的,這可能會導致你在設計時只能考慮多輪對話中的上下文,無法結合用戶的地理位置、時間等參數進行設計。
為什么說自定義參數對帶屏語音設備非常重要?因為用戶有可能說完一句話就直接操作屏幕,然后繼續語音對話,如果語音設備不知道用戶在屏幕上進行什么樣的操作,可以認為語音智能平臺是不知道用戶整個使用流程是怎么樣的。
在不同場景下,用戶說的話都可能會有不同的意圖,例如用戶在愛奇藝里說“周杰倫”,是想看與周杰倫相關的視頻;如果在QQ音樂里說“周杰倫”,用戶是想聽周杰倫唱的歌曲。因此,Where除了是用戶在哪座城市,還有就是用戶目前在哪個應用里。
6. 當前使用的語音智能平臺是否支持意圖的自定義排序。其實,意圖匹配并不是只匹配到一條意圖,它很有可能匹配到多個意圖,只是每個意圖都有不同的匹配概率,最后系統只會召回概率最大的意圖。在第五點已提到,在不同場景下用戶說的語句可能會有不同的意圖,所以意圖應該根據當前場景進行匹配,而不只是根據詞槽來識別。因此語音智能平臺支持意圖的自定義排序非常重要,它能根據特定參數匹配某些低概率的意圖,實現場景化的理解。當然,只有在第五點可實現的情況下,意圖自定義排序才有意義。
7. 當前使用的語音智能平臺是否支持聲紋識別。一臺語音設備很有可能被多個人使用,而聲紋識別可以區分當前正在使用設備的用戶到底是誰,有助于針對不同用戶給出個性化的回答。
設計“能聽懂用戶說什么”的智能語音產品
當我們對整個語音智能平臺有較深入的理解后,我們開始設計一套“能聽懂用戶說什么”的智能語音產品。為了讓大家對語音交互設計有深入淺出的理解,以下內容將是為帶屏設備設計一款智能語音系統,使用的語音智能平臺不具備泛化能力,但是它可以自定義參數傳輸和意圖自定義排序。以下內容分為系統全局設計和意圖設計。
全局設計主要分為以下步驟:
1. 對產品賦予一個固定的人物形象
如果跟我們對話的“人”性格和風格經常變化,那么我們可能會覺得這“人”可能有點問題,所以我們要對產品賦予一個固定的人物形象。首先,我們需要明確我們的用戶群體是誰?再根據我們用戶群體的畫像設計一個虛擬角色,并對這個角色進行畫像描述,包括性別、年齡、性格、愛好等等,還有采用哪種音色,如果還要在屏幕上顯示虛擬角色,那么我們要考慮設計整套虛擬角色的形象和動作。完整的案例我們可以參考微軟小冰,微軟把小冰定義成一位話嘮的17歲高中女生,并且為小冰賦予了年輕女性的音色以及一整套少女形象。
2. 考慮我們的產品目的是什么
這將會為用戶提供哪些技能(應用),這些技能的目的是什么?用戶為什么要使用它?用戶通過技能能做什么和不能做什么?用戶可以用哪些方式調用該技能?還有我們的產品將會深耕哪個垂直領域,智能家居控制?音樂?視頻?體育?信息查詢?閑聊?
由于有些意圖是通用而且用戶經常用到的,例如“打開XXX”這個意圖,“打開電燈”屬于智能家居控制意圖,而“打開QQ音樂”屬于設備內控制意圖,“打開哈利波特”有可能屬于電子書或者視頻意圖,所以每個領域都會有意圖重疊,因此我們要對自己提供的技能進行先后排序,哪些是最重要的,哪些是次要的。在這里我建議把信息查詢和閑聊最好放在排序的最后面,理由請看第三點。
3. 建立合適的兜底策略
兜底方案是指語音完全匹配不上意圖時提供的最后解決方案,可以這樣認為:當智能語音平臺技術不成熟,自己設計的語音技能較少,整個產品基本聽不懂人在說什么的時候,兜底策略是整套語音交互設計中最重要的設計。兜底方案主要有以下三種:
(1)以多種形式告知用戶系統暫時無法理解用戶的意思
例如“抱歉,目前還不能理解你的意思”、“我還在學習該技能中”等等。這種做法參考了人類交流過程中多變的表達方式,使整個對話不會那么無聊生硬。這種兜底策略成本是最低的,并且需要結合虛擬角色一起考慮。如果這種兜底方案出現的頻率過高,用戶很有可能覺得你的產品什么都不懂,很不智能。
(2)將聽不懂的語句傳給第三方搜索功能
基本上很多問題都能在搜索網站上找到答案,只是答案過多導致用戶的操作成本有點高。為了有個更好的體驗,我建議產品提供百科、視頻、音樂等多種搜索入口。以“我想看哈利波特的視頻”這句話為例子,我們可以通過正則表達式的技術手段技能挖掘出“視頻”一詞,同時將“我想看”、“的”詞語過濾掉,最后獲取“哈利波特”一詞,直接放到視頻搜索里,有效降低用戶的操作步驟。這種兜底策略能簡單有效地解決大部分常用的查詢說法,但用在指令意圖上會非常怪,例如“打開客廳的燈”結果跳去了百度進行搜索,這時候會讓用戶覺得你的產品非常傻;還有,如果在設計整個兜底策略時沒有全局考慮清楚,很有可能導致截取出來的的關鍵詞有問題,導致用戶覺得很難理解。
(3)將聽不懂的語句傳給第三方閑聊機器人
有些積累較深的第三方閑聊機器人說不定能理解用戶問的是什么,而且提供多輪對話的閑聊機器人可以使整個產品看起來“人性化”一點。由于閑聊機器人本身就有自己的角色定位,所以這種兜底策略一定要結合虛擬角色并行考慮。而且第三方閑聊機器人需要第三方API支持,是三個兜底策略中成本最高的,但效果也有可能是最好的。
由于是聽不懂才需要兜底策略,所以以上三種兜底方案是互斥的。為了讓整個產品有更好的體驗,我們不能完全依賴最后的兜底策略,還是需要設計更多技能和意圖匹配更多的用戶需求。人與機器的對話可以概括為發送指令、信息查詢和閑聊三種形式,以上三種兜底方案在實際應用時都會有所優缺點,設計師可以根據實際需求選擇最合適產品的兜底策略。
4. 查看語音智能平臺是否提供了與技能相關的垂直領域官方詞典
查看語音智能平臺是否提供了與技能相關的垂直領域官方詞典,如果沒有就需要考慮手動建立自己的詞典。手動建立的詞典質量決定了你的意圖識別準確率,因此建立詞典時需要注意以下幾點:
(1)詞匯的覆蓋面決定了詞典質量,所以詞匯量是越多越好。
(2)該詞典是否需要考慮動態更新,例如名人、視頻、音樂等詞典都應該支持動態更新。
(3)該詞匯是否有同義詞,例如醫院、學校等詞匯都應該考慮其他的常用叫法。
(4)如果想精益求精,還需要考慮詞匯是否是多音字,還有是否有常見的錯誤叫法。有時ASR(Automatic Speech Recognition,自動語音識別)會將語音識別錯誤,因此還需要考慮是否需要手動糾正錯誤。
5. 在場景的幫助下,我們可以更好地理解用戶的意圖
由于我們的大部分設備都是使用開源的安卓系統,而且語音應用和其他應用都相互獨立,信息幾乎不能傳輸,所以我們可以通過安卓官方的API獲取棧頂應用信息了解用戶當前處于哪個應用。如果用戶當前使用的應用是由我們設計開發的,我們就可以將用戶的一系列操作流程以及相關參數傳輸給服務器進行分析,這樣有助于我們更好地判斷用戶的想法是什么,并前置最相關的意圖。
6. 撰寫腳本
腳本就像電影或戲劇里一樣,它是確定對話如何互動的好方法。可以使用腳本來幫助確認你可能沒考慮到的情況。撰寫腳本需要考慮以下幾點:
(1)保持互動簡短,避免重復的短語。
(2)寫出人們是如何交談的,而不是如何閱讀和寫作的。
(3)當用戶需要提供信息給出相應的指示。
(4)不要假設用戶知道該做什么。
(5)問問題時一次只問一個信息。
(6)讓用戶做選擇時,一次提供不超過三個選擇。
(7)學會使用話輪轉換(Turn-taking)。話輪轉換是一個不是特別明顯但是很重要的談話工具,它涉及了對話中我們習以為常的微妙信號。 人們利用這些信號保持對話的往復過程。缺少有效的輪回,可能會出現談話的雙方同時說話、或者對話內容不同步并且難以被理解的情況。
(8)對話中的所有元素應該可以綁定一起成為簡單的一句話,這些元素將是我們意圖設計中最重要的參數,因此我們要留意對話中的線索。
7. 最后我們要將腳本轉化為決策樹
決策樹跟我們理解的信息架構非常相似,也是整個技能、意圖、對話流程設計的關鍵。這時候我們可以通過決策樹發現我們整個技能設計是否有邏輯不嚴密的地方,從而優化我們整個產設計。
以上是全局設計的相關內容,以下開始講述意圖設計。
意圖設計主要包括以下內容:
1. 在前面提到,意圖識別是由詞槽(參數)和槽位(參數數量)決定的
當一個意圖的槽位越多,它的能力還有復用程度就越高;但是槽位越多也會導致整個意圖變得更復雜,出錯的概率就會越高,所以意圖設計并不是槽位越多就越好,最終還是要根據實際情況而決定。當我們設計詞槽和槽位時,請結合當前語言的語法和詞性一起考慮,例如每一句話需要考慮主謂賓結構,還有各種的名詞、動詞、副詞、量詞和形容詞。
2. 當語音智能平臺泛化能力較弱時,我們可以考慮手動提升整體的泛化能力
主要的做法是將常用的表達方式抽離出來成為獨立的詞典,然后每個意圖都匹配該詞典。
3. 如果設計的是系統產品,我們應該考慮全局意圖的設計
例如像帶屏智能音箱、投影儀都是有實體按鍵的,我們可以考慮通過語音命令的方式模擬按鍵操作從而達到全局操作,例如“上一條”、“下一個”、“打開xxx”這些語音命令在很多應用內都能用到。
以下通過簡單的案例學習一下整個意圖是怎么設計的,我們先從“開啟關閉設備”意圖入手:
(1)首先我們設計“執行詞典”和“設備詞典”,詞典如下:
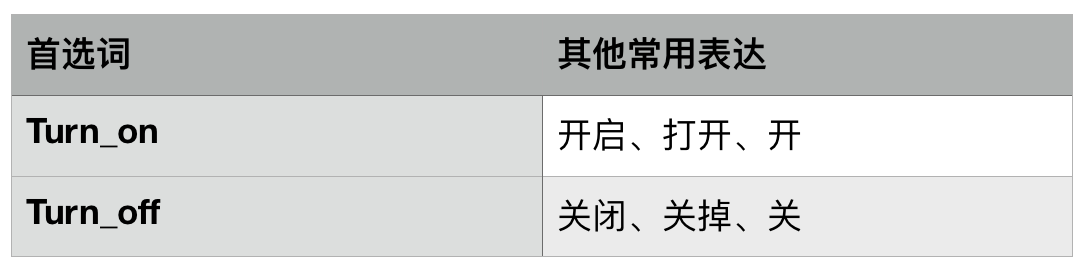

(2)設計“執行設備”的詞槽為“執行”+“設備”。無論用戶說“開燈”或者“打開光管”時都能順利匹配到“Turn_on”+“Light”;而用戶說“關掉彩電”或者“關電視”都能順利匹配到“Turn_off”+“Television”,從而執行不同的命令。
(3)為了增加泛化能力,我們需要設計一個“語氣詞典”,詞典如下:

(4)增加意圖槽位
這時候把“執行”和“設備”兩個槽位設置為必選槽位,意思是這句話這兩個詞槽缺一不可,如果缺少其中之一需要多輪對話詢問,或者系統直接無法識別。
接著增加兩個可選槽位,同時為“語氣”,可選槽位的意思是這句話可以不需要這個詞都能順利識別。這時候用戶說“請開燈”、“能不能幫我開燈”都能順利匹配到“Please”+“Turn_on”+“Light”以及“Please”+“Turn_on”+“Light”+“Suffix”,由于“Please”和“Suffix”都屬于“語氣”可選詞槽的內容,所以兩句話最后識別都是“Turn_on”+“Light”。
通過參數相乘的方式,我們可以將整個“開啟關閉設備”意圖分別執行4種命令,并泛化數十種常用表達出來。
剛剛也提到,對輪對話的目的是為了補全意圖中全部必選詞槽的內容。當用戶家里存在數盞燈時,系統應該將剛才的常用表達升級為“Please”+“Turn_on”+“Which”+“Light”+“Suffix”。當用戶說“打開燈”的時候,系統應該詢問“您需要打開的哪一盞燈”,再根據用戶的反饋結果執行相關命令。
以上的案例只是整個意圖設計中的一小部分,還有很多細節需要根據實際情況進行設計。完成整個全局設計和意圖設計后,我們應該邀請用戶進行實踐與測試,這時候們很有可能發現用戶會用我們沒想到的話術進行語音交互,我們要盡可能地完善意圖以及對話設計,避免產品上線后出現問題。
最后,關于創建用戶故事、撰寫腳本和對話流程設計,請閱讀Google的《Actions on Google Design》和Amazon的《Amazon Alexa Voice Design Guide》兩份文檔以及相關的語音智能平臺的官方使用文檔,里面會更詳細地介紹相關細節。
最后的最后,衷心感謝騰訊MXD團隊翻譯的《Actions on Google Design》以及余小璐和王帆翻譯的《Amazon Alexa Voice Design Guide》兩份中文文檔。
#專欄作家#
無線翡翠臺,微信公眾號:薛志榮,人人都是產品經理專欄作家。全棧開發者,專注于交互設計和人工智能設計。
本文原創發布于人人都是產品經理。未經許可,禁止轉載。
題圖來自Pixabay,基于CC0協議