
本篇文章介紹了當前語音交互產品的一些尷尬局面,對于這些“尷尬”,當前人們正在探索解決的辦法。

近幾年,自然語言處理技術的飛速發展,把語音交互的話題再次引爆。甚至有的公司已經開始招聘語音產品經理和語音交互設計師。也有人判斷,未來這將成為下一波熱門崗位。
去年雙十一,天貓精靈走進了千家萬戶。剛開始的時候,大家都對這些語音交互類產品充滿了期待。然而時隔一年多之后再看,這些產品似乎并沒有如預料中的那樣,改變人們的生活。那些天貓精靈的用戶們對產品的評價只有兩個字:很笨。
如今,人工智能的技術早已經遠遠超過五年之前了,但是從Siri的出現一直到現在,大家對語音交互類的產品評價從來沒有變過,那就是:很笨。語音產品似乎總是處于一個尷尬的位置。
要理解這一點,我認為僅僅從技術角度分析是完全不夠的,現在人工智能的技術,解決的只是語音識別的問題。語音識別的技術是越來越強大了,甚至能聽懂方言了。但是,“笨”是一個用戶腦子里面的概念,就算聽得懂方言了,語音產品仍然只是一個能聽懂方言的“傻子”。
如果不能從哲學和認知科學的角度去分析用戶為什么會認為這些產品笨,那么我們對語音交互的認知會掉進一個死胡同中。
為了說明這個問題,我們一步步來,先理解一個概念:交互的邊界。
一、交互的邊界
當我們與機器進行交互時,我們能對機器做的事情是限定在一個有限的范圍之內的(也就是說指令是一個有限集合),我把這個范圍定義為交互的邊界。
傳統的視覺交互界面,都是有邊界的交互。并且,交互的邊界需盡量明確。交互設計有一條很重要的原則,叫做可視化原則,就是指需要把用戶能夠進行的操作都讓用戶看到。把交互的邊界展示給用戶,不要讓用戶去尋找邊界。
視覺界面的交互下,用戶所有的操作,都是設計者預先設計好的。用戶做的只是“選擇題”,并且用戶也知道,只能做“選擇題”。
語音交互對于計算機來說,只是信息的程現方式不同,其邊界的性質并沒有發生變化。于是就有了最原始的、沒有火起來的語音交互形式,選擇題的形式:“個人服務請按1,公司服務請按2,人工咨詢請按0”。這種語音交互是邊界清晰,運作良好的,也從來沒有用戶會用“笨”來形容它們。
然而,語音交互就老老實實像視覺交互一樣做選擇題不好嗎?為什么視覺交互人們從來不提到人工智能,而語音交互,人們總是把它和人工智能搞混在一起?
我們來看第二個概念:信息的維度。
二、信息的維度
聽覺信息和視覺信息,在物理屬性上面是完全不同的。
視覺信息,是空間二維的信息,且在時間這個維度上是可以持續的。
聽覺信息,是空間零維的信息,其存在僅僅只能在時間這個維度上閃現。
于是,在呈現交互的邊界時(也就是提供“選擇題”的選項時),視覺界面可以在時間空間中呈現任意復雜的界面,完成復雜高效的操作;而語音界面,其選項在被呈現的同時也在消逝,必須依靠人的短時記憶把選項存儲下來。
而人的短時記憶容量非常有限的,只能存儲7個簡單的信息模塊。于是,傳統語音界面的復雜程度,被限制在了人短時記憶容量的范圍之內。這么小的信息量,注定了這種有邊界的語音地位尷尬,只能“小打小鬧”。不太可能成為一種重要的交互方式。
三、人與現實世界的交互
在反觀我們現實世界,我們基于視覺信息所做的事情,都是類似于“選擇題”,比如看到一個按鈕按下,看到一雙筷子拿起。只有當空間中存在這個“選項”時,我們才能操作。
也就是說,我們基于視覺信息與現實世界進行的交互,依然類似于有邊界的“選擇題”。
然而,人與人進行語音交互的時候,卻不是在做選擇題,而是模糊邊界的(我們可以理解為沒有邊界)。你說話的內容,并不需要在對方提供的選項之中,你發出的信息可以是創造性的。
正是因為人與人之間的語音交互是邊界模糊的,才使得語音溝通的信息量突破人類短時記憶的限制,成為人與人溝通最重要的方式。
所以,人機語音交互想要成為一種重要的交互方式,必然需要突破傳統“選擇題”的方式,成為一種沒有邊界的交互。也就是說,用戶可以隨意發出符合場景的指令,而不能讓機器告訴用戶它聽得懂什么。
四、語音與人工智能
然而,當你不知道機器能聽懂什么的時候,你只能假象對方像一個人樣,什么都能聽得懂。于是,語音交互一旦突破了傳統的邊界,就會一發不可收拾地朝著的方向發展。
當你聽到電話語音給你選項邊界的時候,你不會假想對方是人;但是對于Siri這種沒有提供邊界的交互,你很自然的就把對方假象成為一個有智能、有情感的生物。
很多人喜歡調戲Siri,正是因為你已經把他假象成了一個人,而當它遠遠沒有達到一個正常人應該具備的決策和判斷能力時,你就會形容它很笨。
語音交互在剛剛開始的時候,他對標的對象就已經是真實的人。只存在“像人”“不像人”兩種狀態,而不像視覺界面,人們或許還愿意去學習它的交互。
為了說明視覺交互和語音交互的這點不同,需要舉一個例子:一個農村老太太,當她使用一個視覺界面產品的時候,如果她不知道該怎么操作,她可能會責怪自己笨;但是如果是一個語音交互產品,她無法與其進行正常交互的時候,老太太一定會認為是語音交互產品很笨。這就是語音交互的尷尬。
真正的語音交互要想發揮其價值,其最終的效果,就是像人與人語言交流一樣的邏輯進行交流。所以語音交互的發展總是期待人工智能技術的突破。
然而,現在人工智的水平到底如何?是否真如大家所說的奇點臨近。這點誰也沒有辦法判斷,但是,從認知科學的角度,我能為你提供一些思路。
五、當前人工智能的發展階段
近年來,深度神經網絡的快速發展確實非常恐怖。理解神經網絡算法的人應該都懂,神經網絡算法的底層邏輯已經不同于傳統機器邏輯判斷的算法,而是類似于人類神經系統激活的方式工作。這是大家認為機器可能會超過人類的重要原因。
然而,從認知科學的角度來說,現在的人工智能依然非常初級。人的認知分為:感覺,知覺,注意,記憶,表象,思維,想象,等等。而感覺知覺,是人類最低級別的認知,也是被研究的最多的認知現象。而表象、思維、想象等認知現象,現在科學研究得還不多,這也是人類認知最為神秘的地方,這也正是很多宗教或者迷信認為人類存在靈魂的原因。
而我們再來看看現在人工智能的前沿領域:圖像識別,自然語言處理,等等,從認知科學的角度來說,都相當于人類感覺知覺階段。遠遠沒有到達表象,思維,想象。
但是近年來,AlphaGo在圍棋領域的表現讓有些人開始懷疑,也許人類更高級的思維能力的機制和感知覺機制是一樣的。到底人工智能能否突破認知領域的研究,超越人類,或者也許人工智能的發展會像一座巴別塔,永遠也無法到達目標,我們不做討論。
此路我們看不到明確終點,也許可以換一個思路。語音交互并不一定要依賴通用人工智能達到人類意識的水平,而是可以通過對人類認知邏輯的直接模擬,來實現像人與人溝通一樣的體驗。雖說人與人之間的交流是沒有明確邊界的交互,但是仍是有規律可循的。
最典型、最重要的一個特點,就是無意識推理:人與人溝通過程中,總是在不斷地進行無意識推理,并且也假象對方能進行無意識推理。
絕大多數情況下,用戶認為語音產品笨,就是因為語音產品缺少無意識推理這個認知邏輯。

六、無意識推理
一篇文章不可能道盡所有的無意識推理,只講幾個點,拋磚引玉。
1. 環境背景推理
我們常用的智能音箱和智能車載,都有一個激活指令。你在家里,哪怕只有一個人的時候,你也需要呼叫:“天貓精靈”,它才能夠激活。這種在連續對話中顯得尤其不方便。當我中間停了一會,再和它說話的時候,說完我才發現我白說了,又得重新呼叫名字激活。這是一種非常反人類的交互。
正常人與人語音交流時,并不是通過這種激活的邏輯,而是過濾的邏輯。人的聽覺系統是隨時在線的,我聽到一句話,如果潛意識里我知道屋里就我們兩個人,我就會立馬處理這條信息,做出響應。
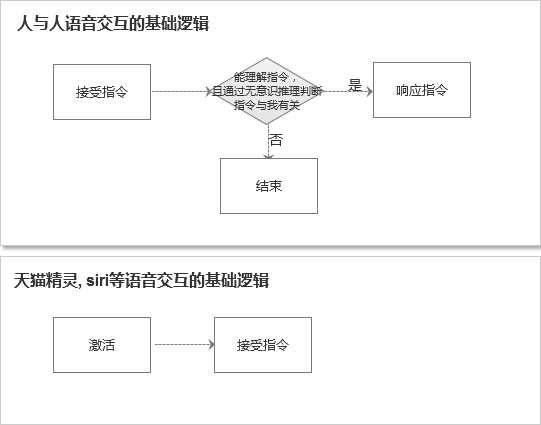
如上圖所示,人與人交互的邏輯與語音產品交互的邏輯是不同的。人與人的交互是隨時在線,然后過濾信息的;然而現在的語音產品,雖然技術本質上也是隨時在線的,但是對用戶來說,卻多了一個激活的過程,相當于手動按下開關。
如果屋里有多個人會怎么樣?我會先等一會,發現沒有人回應時,我就會確認:“是在和我說話嗎?”然后繼續這次對話。
以此類推,人每時每刻在利用環境信息進行無意識的推理的,模擬這一點,我們在做語音產品的時候,我們可以考慮把多個維度的環境信息的數據結構化,存儲在一個緩存中,將用戶發出指令與環境信息進行邏輯運算之后,再做出響應。
比如車載就特別容易做到這一點,通過座位的傳感信息,很容知道車上有幾個人。
2. 多通道(多模態)信息推理
一群熟人坐在一起的時候,沒有誰說話之前總是要叫對方名字的。我看你一眼再說話,就表示我在對你說。人的表情,動作等視覺信息,在語音溝通中也是非常重要的。
單純的語言信息存在很多缺陷,于是人類在語言信息溝通的過程中,也需要借住視覺或其他通道收集到的信息來輔助理解判斷,否則語言交流的難度會大很多。
在高級的語言溝通中,這些信息非常復雜,但是對于對于不太復雜的語音產品,最重要的就是”目光指向”。別看這只是一個簡單的邏輯,但是在人較多的環境下,能起到非常大的作用。
天貓精靈有個烏龍事件,當你把他音量調到最大播放熱鬧的音樂的時候,它就聽不到你任何指令了。但是在嘈雜的環境中,人與人是怎么溝通的呢?我會看著你說一句話,然后你會表現出聽不清的表情,然后把我拉到一個安靜的地方溝通。
所有如果語音產品能夠利用視覺通道的信息,對于語音交互的流暢度也是非常有幫助的。比如說,在大聲播放音樂的環境中,當天貓精靈“看到”了我轉向它說話的時候,他應該自動將音量臨時調小聽我再說一遍。
再比如,如果你家里同一個房間有多個燈。如果你想通過智能音響關燈的話,你必須要給每個燈取一個名字,這種交互非常不自然,而且還容易忘記。但是如果能利用視覺通道的信息進行輔助判斷,那么你只要用手指著這個燈說:“關這個燈”。
3. 上下文指代信息推理
人與人溝通過程中,上下文也是非常重要的。上下文信息最重要的作用在于代詞的指代。要做到自然語言交互,指代信息必不可少。
linda說:“最近有哪里好玩嗎?”
Alice說:“附近開了一個游樂場不錯。”
Linda說:“我們就去那里吧。”
最后一句話的“那里”,是指代的“游樂場”。這種使用代詞的交互方式在人與人交互的過程中是非常常見且重要的。人與人交互的過程中,會在短時記憶里存儲最近談話中涉及到的對象。當對話中遇到代詞時,會無意識地從短時記憶中提取對象代入語句,從而理解。
天貓精靈目前好像還完全不支持指代關系,顯得非常笨。而最近幾個版本的siri開始可以支持指代關系(以前的也不行)。比如說當你用Siri搜索過一個地點之后,你說:“去那里”。它會知道你是要去最近搜索的地點。說明他把最近搜索的對象存存起來了。使得上下文聯系起來,而不是獨立存在。
但是實際溝通過程中的指代關系遠比這復雜。尤其是當人物、地點、事物等指代關系同時出現的時候。還需要更加深入理解人的認知模型,才讓機器實現與人更流暢的交互。
總結
語音產品雖然已經有很長的發展歷史了,但是今天的語音產品仍然像是一個新的領域。并且,當今的語音產品地位也比較尷尬,一方面,語音識別技術快速發展,機器的語音識別能力已經超過人類,但是另一方面,更高層次的語言認知模型并沒有被計算機科學家考慮在內,使得語音產品實際使用起來的時候,總是顯得很笨。
想要優化語音交互的體驗,腳踏實地地讓語音交互發揮更大的價值,釋放語音交互的生產力,需要更深入的從認知科學的角度,理解人類對語言的認知模型,做到人與語音產品的自然交互。
本文由 @ArvinNing 原創發布于人人都是產品經理。未經許可,禁止轉載。
題圖來自Unsplash,基于CC0協議。