
本文介紹了設計好的AI用戶體驗時需要牢記的三個基本原則——期望、錯誤和信任。

在先前的文章,我談到了《AI 開發指南:機器學習產品是什么?》,AI及ML產品需要更多的試驗、反復調整,也因此帶來更多的不確定性。 關于什么是AI及ML產品,在《如何設計和管理AI產品?》這篇文章里有更詳細的說明。
因此,我們需要為ML工程師和數據科學家提供足夠的空間和彈性,來探索可能的解決方案。 同時也需要明確定義目標函數(objective function),并鼓勵團隊盡早測試,以免失去方向。
為AI&ML 產品設計用戶體驗 (UX) 時,同樣面臨這樣的挑戰。 在過去的幾個月里,我與UX團隊合作,收集客戶意見并改進ML產品的用戶體驗。 以下是我們學到的三件最重要的事情:
三個基本原則:期望、錯誤和信任
建立用戶正確的期望Set the Right Expectations
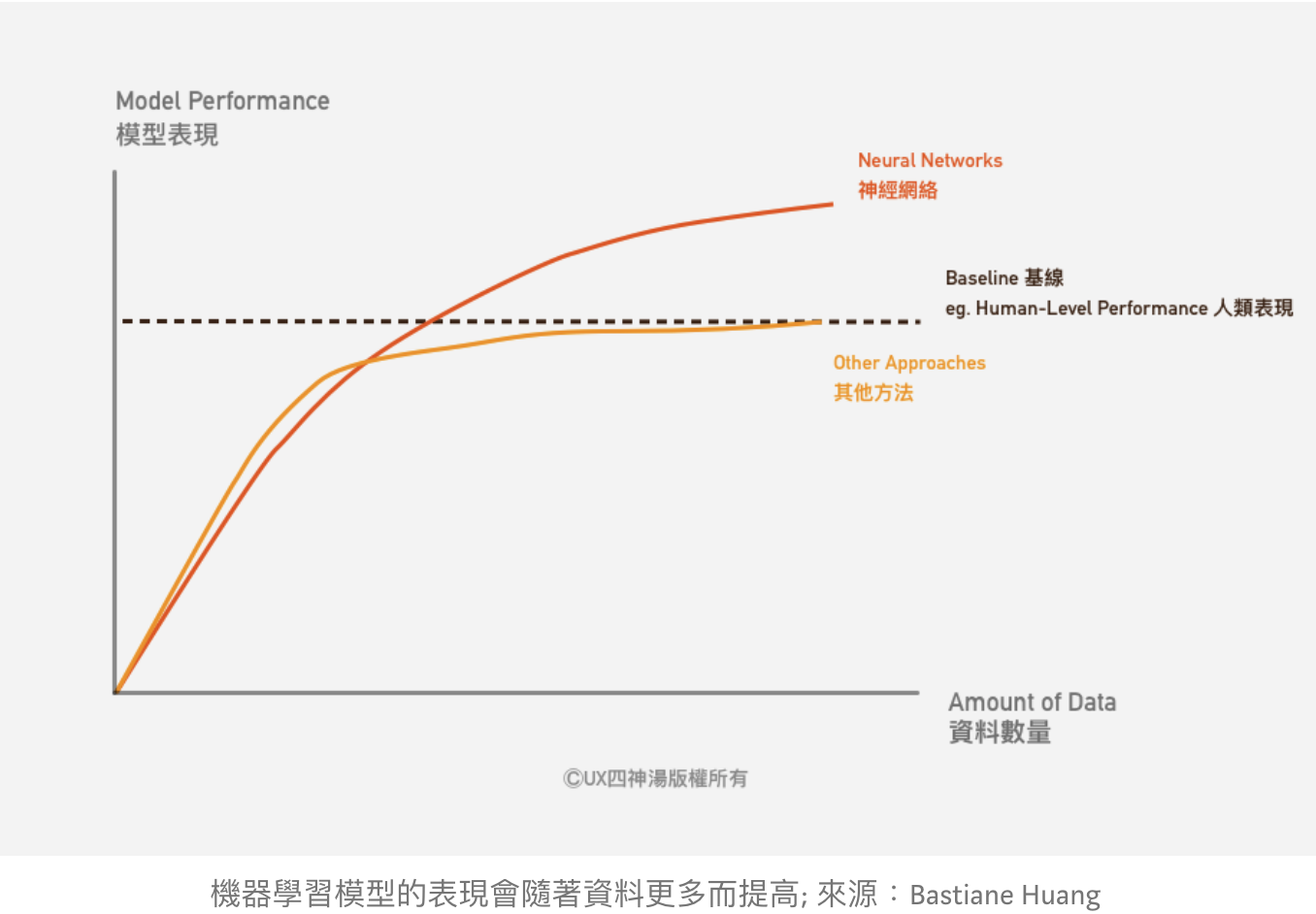
機器學習模型的表現會隨著數據更多而提高,也就是說,ML模型會不斷自我進步,這是使用AI&ML最大的好處之一。 但這也意味著,他們一開始的表現不會是完美的。
因此,必須讓用戶了解ML產品不斷進步的本質。 更重要的是,我們需要與用戶合作,事先確定一套驗收標準(acceptance criteria)。 只有當ML模型符合驗收標準時,我們才會推出該項產品。
設置驗收標準時,可以比較系統的基準性能(baseline performane),替代或現有解決方案的性能,或甚至是比較標準答案(ground truth),
例如:比較人工翻譯及機器翻譯的準確度。 或是將機器預測的天氣數據,拿來與真實天氣數據做比較。 又或是將機器包裝的速度及準確度,與人工操作比較,客戶可以設定:唯有ML模型的準確度到達人工的90%才能上線。
有時,制定驗收標準可能比想象中復雜:你可能有多個不同的用戶類型,他們需要不同的驗收標準。 或者,你的使用案例要求在某個特殊項目必須完全沒有錯誤。
另外需要注意的是,模型本身的準確性通常并不是最好的衡量標準,一般需要考慮精確度(Precision)和召回率(Recall)之間的權衡。 這在前一篇文章有更詳細的說明。
如果用戶需要ML模型從第一天開始就有很好的表現,可以預先訓練的模型(pretrained model):是先搜集數據,確定模型達到驗收標準。
但是,要注意的是,即使使用預先訓練的模型,例外情況(edge case)仍可能發生。 你需要與用戶合作,制定計劃降低風險。例如:如果模型不起作用,有什么備案? 如果用戶想要添加新的使用案例,需要多長時間重新訓練模型? 需要多少額外的數據? 當不允許更新模型時,用戶是否可以設置更新中斷期? 這些問題都需要事先回答。
通過建立用戶的正確期望,你不僅可以避免用戶挫折,甚至可以讓用戶感到驚喜。 亞馬遜搭載Alexa語音助理的智能型喇叭就是一個很好的例子。 我們對類人形機器人有很高的期望:我們預期它們可以像人類一樣自然交談和動作。
所以,當智能機器人Pepper(下圖)沒有辦法和我們進行流暢的對話時,我們感到沮喪,不想再使用它。 相比之下,Alexa 定位為智能型喇叭,降低了客戶的期望。 當我們了解到它不僅僅可以播放音樂,還有很多其他的功能時,就能夠讓用戶感到預期外的驚喜。
保持信息公開透明(transparency)是加強溝通和信任的另一個重要部分。 ML 比軟件工程更具不確定性。 因此,顯示每個預測的信賴區間(confidence level),也是建立正確期望的一種方式。 這么做也能夠讓用戶更了解算法的工作原理,從而與用戶建立信任。
建立信任(Build Trust)
ML算法通常缺乏透明度,就像一個黑盒子,我們知道輸入(例如圖像),和輸出預測(例如,圖像中的對象/人員是什么)分別是什么,但不知道盒子里是如何運作的。 因此,向用戶解釋ML模型如何運作很重要,可以幫助我們建立信任,和獲得用戶支持。
如果不對算法多做說明,有可能會讓用戶感覺被疏遠,或感覺產品不夠人性化。 例如,優步司機抱怨說Uber算法感覺非人性化,他們質疑算法的公平性, 因為算法所做的決定,并沒有給他們明確的解釋。 這些駕駛也認為算法搜集很多他們的數據,對它們非常了解,但他們對算法的工作原理和決策卻了解的很少。
相反的,亞馬遜的網頁很清楚地告訴用戶為什么他們推薦這些書。 這只是一個簡單的單行解釋。 告訴用戶其他看過該項產品的用戶還瀏覽過什么商品,但卻可以讓用戶大致了解算法的原理,讓用戶可以更好地信任推薦系統。

同樣的優步司機研究也發現,司機覺得他們經常被監視,但他們不知道這些數據將用于什么用途。 除了遵守 GDPR 或其他數據保護法規外,還應該嘗試讓用戶了解他們的數據是如何被管理的。
優雅地處理錯誤(Handle Errors Gracefully)
“… 也有未知的未知-那些我們不知道我們不知道的… 這一類往往是最困難的”
——唐納德· 拉姆斯菲爾德
“… But there are also unknown unknowns — the ones we don’t know we don’t know… it is the latter category that tend to be the difficult ones”
——Donald Rumsfeld
在設計系統時,通常很難預測系統會如何出錯。 這就是為什么用戶測試和質量保證(Quality Assurance),對于識別失敗狀態(fail state)和例外情況(edge case)極其重要。 在實驗室或實際現場,進行更多的測試,有助于最大限度地減少這些錯誤。
你也需要根據錯誤的嚴重性和頻率進行分類和處理。 有需要通知用戶并立即處理的致命錯誤(fatal error)。 但也有一些小錯誤,并沒有真正影響系統的整體運作。 如果你每個小錯誤都通知用戶,那會非常煩人,干擾用戶的產品體驗。 相反的,如果不立即解決致命錯誤,那可能會是災難性的。
你可以將錯誤視為用戶期望和系統假設之間預期之外的交互(unexpected interactions between user expectations and system assumptions):
- 用戶錯誤User Error:當用戶”誤用”系統時,導致的錯誤。
- 系統錯誤System Error:當系統無法提供用戶期望的正確答案時,就會發生系統錯誤。 它們通常是由于系統固有的局限性造成的。
- 情境錯誤Context Error:當系統按預期運作,但用戶確察覺到錯誤時,這就是情境錯誤。 這通常是因為我們設計系統的假設是錯誤的。
舉例來說,如果用戶不斷拒絕來自App應用的建議,產品團隊可能需要查看并了解原因。 例如,用戶可能從日本搬到了美國,但是應用程序錯誤地根據用戶的日本信用卡信息,假設用戶居住在亞洲。 在這種情況下,用戶的實際位置數據可能是提出此類建議的更好數據依據。
最棘手的錯誤類型是未知未知(the unknown unknowns):系統無法檢測到的錯誤。 像上面的例子就是屬于這種錯誤類型,必須要回去分析數據或異常模式,才有可能察覺。
另一種方法是允許用戶提供回饋feedback:讓用戶能夠很容易地,隨時隨地提供回饋。 讓用戶幫助你發現未知未知,或是其他類型的錯誤。
你也可以利用用戶回饋來改進你的系統。 例如。 YouTube 允許用戶告訴系統他們不想看到的某些建議。 它還利用這一點收集更多數據,使其建議更加個人化和準確。


將ML模型預測作為建議,而不強制用戶執行,也是管理用戶期望的一種方式。 你可以為用戶提供多個選項,而不指定用戶應執行哪些操作。 但請注意,如果用戶沒有足夠的信息來做出正確的決策,這個方法就不適用。
我們之前談到的許多一般原則仍然適用在這里。 你可以在我上一篇文章中找到更多詳細信息。
如何設計和管理AI產品?
- 定義好問題并盡早測試:如果聽到有人提議”讓我們先構建ML模型,看看它能做什么。 ”通常要很小心,沒有定義好問題前就試圖開發產品,通常會浪費團隊大量時間。
- 知道何時應該或不應該使用ML。
- 從第一天就開始計劃數據策略。
- 構建ML產品是跨領域的,牽涉到的職能并不只是機器學習而已
作者:Bastiane Huang,擁有近10年產品及市場開發管理經驗,目前在舊金山擔任 AI/Robotics新創公司產品經理,專注于開發機器學習軟件,用于機器人視覺和控制。
本文由 @Bastiane 原創發布于人人都是產品經理,未經許可,禁止轉載
題圖來自Unsplash,基于 CC0 協議。