
隨著智能音箱、智能家居等智能硬件的普及,語音交互熱度也不斷飆升。想要了解語音交互,第一步是了解麥克風陣列,本文從概念、分類、作用幾個方面對麥克風陣列展開了說明,與大家分享。

語音交互從亞馬遜音箱(Echo)誕生的那一刻,就逐步走進了人們的視野,越來越多的人開始接觸到語音交互的設備。從電視里的機器人,到家里的音箱,最后到手上的手機,語音交互變得觸手可及。
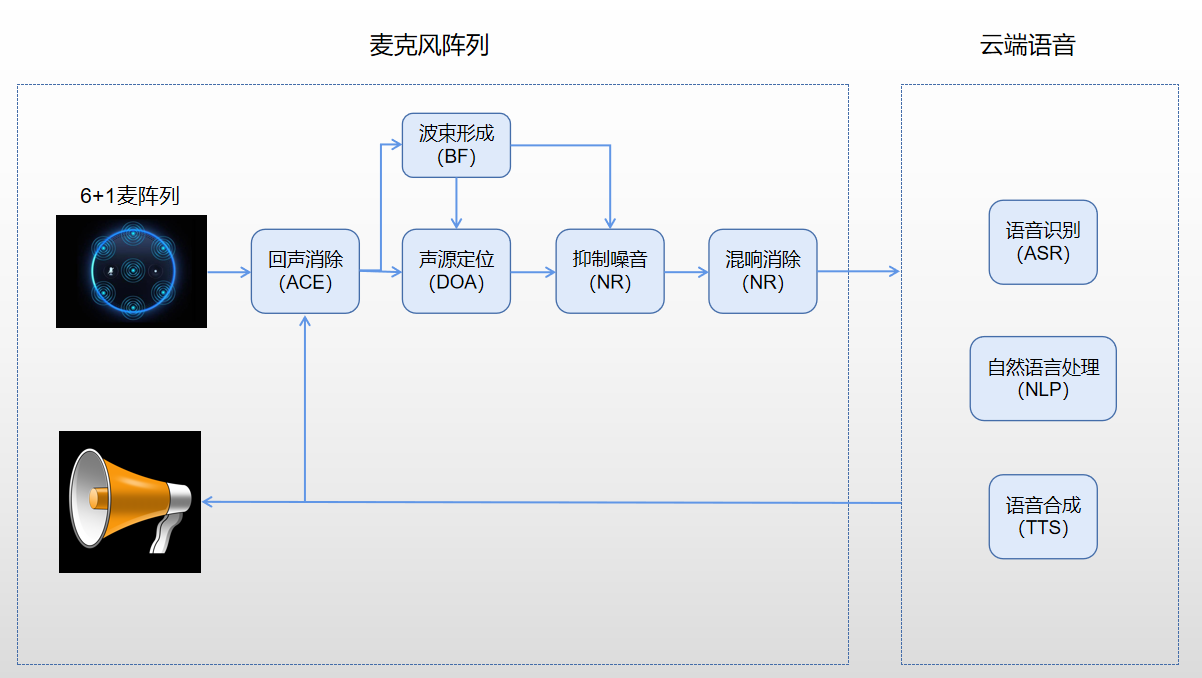
語音交互的第一步就是拾音,機器人先要有一個耳朵,因為聽不到聲音就不會有反饋,更談不上交互了,而麥克風陣列就相當于機器人的耳朵。
一、什么是麥克風陣列?
麥克風相信大家都見過,就是我們常見的話筒,麥克風陣列本質上和話筒沒有區別,只是收音的單元比較多而已,基本上超過兩個收音孔就可以說是麥克風陣列了。簡單理解為一個麥克風就是麥克風,多個麥克風就是麥克風陣列。
麥克風陣列是由一定數目的聲學傳感器(麥克風)按照一定規則排列的多麥克風系統,對聲場的空間特性進行采樣并濾波的系統。
麥克風陣列除了看到的麥克風數量以外,還有一系列的前端算法,兩者結合的系統才是完整的麥克風陣列。而麥克風陣列也只是完成了物理世界的音頻信號處理,想要完成語音識別,還是需要云端的ASR模型,兩個系統配合在一起才能得到最好的識別效果。
二、麥克風陣列如何分類?
由于前端算法看不見,摸不著,我們對于麥克風陣列的分類,常常參考麥克風的布局和數量。目前常見的分類,基本上以麥克風布局的形狀來做區分,參考我們中學課本講的點線面體,可以將麥克風陣列分為:線性陣列,平面陣列,立體陣列(點就是一個麥克風)。
當然也有根據形狀的分類,比如:一字、十字、平面、螺旋、球形及無規則陣列等。這里我們按照點線面體的方法介紹。
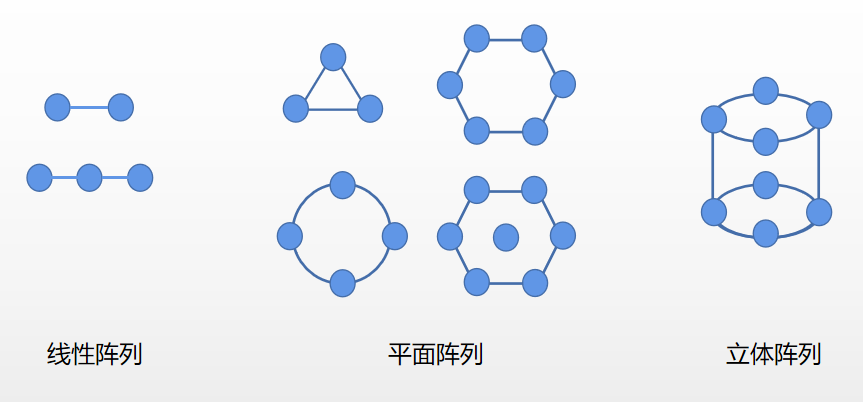
1. 線性陣列
常見的是兩個麥克風的組成的線性陣列,目前幾乎所有中高端手機和耳機都采用雙麥克降噪技術來提升通話效果,也有部分智能音箱采用這種方案。
兩個麥克風組成的線性陣列最大的優勢就是成本低,相對于多麥克風,功耗也更低。缺點也比較明顯,降噪效果有限,就是對于遠場景交互的效果并不好。
2. 平面陣列
平面陣列的組合就比較多樣化,常見的有4麥陣列和6麥陣列,還有升級的4+1麥陣列和6+1麥陣列,甚至8+1麥陣列。平面陣列常見于智能音箱和語音交互機器人上面。
平面陣列的線性陣列可以實現平面360度等效試音,麥克風個數愈多,空間劃分精細度高,遠場景識別效果好。缺點就是功耗較高,ID設計復雜。
3. 立體陣列
立體陣列多是球狀,或者圓柱體,可以實現真正的全空間360度無損拾音,解決了平面陣高俯仰角信號響應差的問題,效果是最好的,成本也是最高的。但是生活中用的比較少,常見于專業領域。
三、麥克風陣列有什么作用?
前面從硬件的角度介紹了麥克風陣列的分類,接下來結合麥克風陣列前端算法,看看麥克風陣列到底有什么作用?
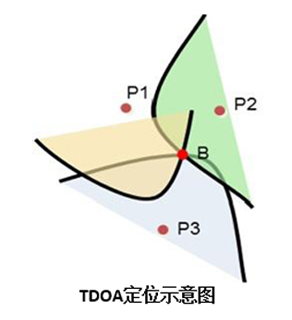
1. 聲源定位
人有兩個耳朵,可以通過聲音判斷發聲的方向,機器人也同樣可以做到。這個功能就是聲源定位,通過聲音感知人所在的方向,從而實現對目標聲源方向的跟蹤。這也為后續的波束形成做技術鋪墊。
比如機器人場景,我們在機器人左邊叫它,機器人聽到聲音后就會把頭轉向左邊,我們在機器人背后叫它,機器人聽到聲音后就會轉過去,這就是聲源定位最典型的應用。通常聲源定位會應用在語音喚醒階段,能夠檢測一個大致的方向。
常用到的技術是TDOA(Time Difference Of Arrival,到達時間差),簡單理解就是通過計算信號到達麥克風之間的時間差,從而計算出聲源的位置坐標,需要毫秒級的響應和計算。
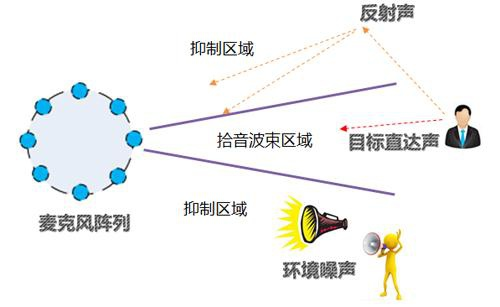
2. 抑制噪音/增強人聲
在語音識別中,語音信息中往往夾雜著噪音,常見的有環境噪音和人聲干擾,通常不會掩蓋正常的語音,只是影響聲音的清晰度。麥克風陣列主要通過波束形成技術,來抑制噪音,增強人聲。可以理解為只識別某個角度的聲音(一般角度可以進行調節),其他角度的聲音都會受到抑制,從而實現抑制噪音的目的。反過來也可以增強角度內的人聲,就是增強人聲。
比如家庭場景,如果我們開著電視和空調在和音箱說話,音箱會以喚醒的它的角度為拾音區域,抑制非該角度的噪音(電視聲音和空調噪音)。一般我們根據使用場景去設置拾音角度,使用距離越遠,角度越小,常見為60°-120°之間。
抑制噪音能夠滿足日常家庭的使用場景,但對于強噪音環境的抑制效果并不理想,典型的就是雞尾酒效音。
3. 回聲消除
如果不做特殊處理的話,機器人會識別自己發出來的聲音,很有可能就會變成無休止的自問自答,或者拾音錯誤。回聲消除就是為了解決這個問題,消除掉機器自己發出的聲音。
比如家庭場景下,你的音箱正在放音樂周杰倫的新歌,但是你想要查一下天氣,這個時候你就會說“小X小X,今天天氣”。回聲消除的目的就是要去掉其中音樂信息而保留你的聲音。
其實回聲消除可能不太好理解,有時也被稱作為“自識別”,即自己識別自己發出的聲音。
4. 混響消除
在某些場景,發音會有回音,人能聽到的是17米左右距離返回的回音。但是機器的感知要比人敏感的的多,如果不做處理,就會出現一句話疊加識別的情況。混響常指聲波在室內傳播時,被墻壁、天花板、地板等障礙物形成反射聲,并和直達聲形成疊加的現象。
比如在演播廳,我們能夠感受到較為明顯的回音,機器同樣能夠識別到這些回音。混響消除就是消除之后帶來的回音,只識別第一遍的內容。
解決了這些問題,基本上就可以在日常環境下進行一個正常拾音,從而保證整個語音識別的正常。
四、如何選擇麥克風陣列?
市面上可選的麥克風陣列方案比較多,國產主要集中在思必馳、云知聲、科大訊飛和智聲科技等,他們也有從單麥克風到麥克風陣列的全套解決方案,以及前端算法。縱觀全球主要是亞馬遜和蘋果的麥克風陣列硬件,谷歌和微軟的前端算法,分別是他們的擅長的地方。

首先從使用場景和ID設計,進行選擇。如果是像手機一樣拿在手上的近場景交互,產品又追求性價比,那么單麥克風完就能夠滿足需求;如果是像音箱一樣放在家庭中的遠場景交互,建議可以選擇4麥以上的麥克風陣列,常見的有4+1和6+1兩種選擇方案;如果是像視頻音箱一樣站在面前的交互場景,建議選擇2-4麥的麥克風陣列,當然條件允許,6麥的,甚至8麥的都是可以的。另外產品的ID設計適合什么類型的麥克風陣列,這個就因人而異了。
其次就是結合產品定位和前端算法,進行選擇。如果只需要近場景收音,需求僅限于拾音,建議單麥就可以,成本低,ID設計簡單;如果是想要實現類似通話降噪這種效果,2麥的麥克風陣列就可以滿足需求,再多價值不大;如果是想要去除大部分噪音,建議使用4個以上的麥克風陣列,還要考慮前端降噪算法的能力,一般大廠效果更加可靠,麥克風陣列的硬件和前端算法的效果要結合ASR識別來一起評估。
還有就是像軍工領域,航空航天,這些高端產品,就可以考慮使用分布式陣列了,這個不在我們考慮的范圍內了。
最后就是參考成本以及研發速度,進行選擇。看了上面這么多介紹,只需要根據自己產品的售價,以及這方面的預算,相信大家都已經清楚該怎么做出選擇了。至于研發速度,個人覺得選擇成熟的方案是最快捷的方式,如果ID設計不兼容,可能也需要定制,看具體需求。
一般像我們把手機拿到嘴邊的語音交互,單個麥克風就夠用了,就像有人在你耳旁說悄悄話,一個耳朵就能聽清楚。但是在面對遠距離,嘈雜環境的語音交互,麥克風陣列相對于單個麥克風有很明顯的優勢。
五、行業內麥克風陣列介紹
我們盤點一下業內常見的產品在麥克風陣列上的使用情況

通過收集素材,發現小米和天貓的音箱產品線覆蓋非常全,其中2麥到6麥的產品都有。其實大部分音箱設備還是采用2麥和6麥的方案,隨著前端算法的進步,未來需要的麥克風可能會越來越少。
六、如何測試麥克風陣列?
評價一個麥克風陣列的優劣,除了麥克風陣列的軟硬件能力,還需要結合ASR的識別效果一起進行評估,以最終的識別結果為準。
我們后面聊到ASR識別的時候,再聊這部分內容。
七、總結
在語音交互普及的今天,消費級麥克風陣列主要解決遠場景交互的語音識別問題,保證真實場景下的語音識別率。
麥克風陣列主要從兩方面來實現物理音頻的獲取,一方面是硬件的麥克風數量和布局,一方面是軟前的前端算法。硬件布局越合理,麥克風數量越多,前端算法可以處理的信息越多,識別的效果越好。如果只有1個麥克風,無論前端算法再怎么牛逼,是無法實現聲源定位的;如果有2個麥克風陣列,前端算法如果超級牛逼,是可以實現大概的聲源定位;如果有6+1麥克風陣列,前端算法就可以輕松的實現聲源定位。
麥克風陣列只是語音識別的一部分,其麥克風布局和數量決定下限,前端算法決定上限。
本文由 @我叫人人 原創發布于人人都是產品經理。未經許可,禁止轉載
題圖來自Unsplash,基于CC0協議