
有意轉行AI行業的PM們,需要對機器學習了解多深?機器學習跟無監督學習、半監督學習、神經網絡、深度學習、強化學習、遷移學習等是什么關系?各自之間又有什么區別和關系?本文作為一篇掃盲篇將給你一一梳理。

01 機器學習(Machine Learning)
1. 什么是機器學習
機器學習與人工智能的關系:機器學習是實現人工智能的一種工具;而監督學習、無監督學習、深度學習等只是實現機器學習的一種方法。
機器學習與各種學習方法之間的關系:
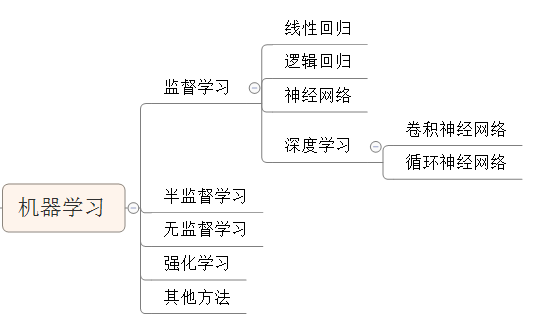
注:這里把神經網絡和深度學習歸到監督學習下面可能不是很恰當,因為維度不一樣,只能說有些監督學習的過程中用到神經網絡的方法。
而在半監督學習或無監督學習的過程中也可能會用到神經網絡,這里只在監督學習的模式下介紹神經網絡。
機器學習就是讓機器自己有學習能力,能模擬人的思維方式去解決問題。
機器學習目的不只是讓機器去做某件事,而是讓機器學會學習。就像教一個小孩,我們不能教他所有的事,我們只是啟蒙他,他學會用我們教他的東西去創造更多的東西。
人解決問題的思維方式:

遇到問題的時候,人會根據過往的經歷、經驗、知識,來做決定。
機器模擬人的思維方式:
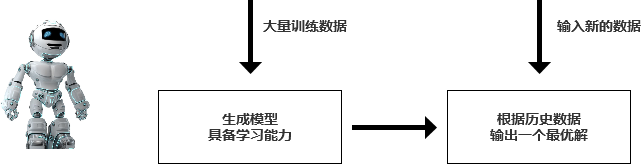
先用大量的數據訓練機器,讓機器有一定的經驗,再次輸入新的問題時,機器可以根據以往的數據,輸出一個最優解。
所以,機器學習就是讓機器具備學習能力,像人一樣去思考和解決問題。
2. 怎么實現機器學習
實現機器學習的三個步驟:

舉個例子:我們現在要做一個預測房價的模型,假設影響房價的因素只有住房面積:
第一步:定義模型
假設:y=房價,x=住房面積
則定義模型:y=a*x+b
其中x為特征變量,a、b為參數。因此我們的目的就是利用訓練數據(Training Data),去確定參數a、b的值。
第二步:定義怎樣才是最好的(定義代價函數)
在第一步定義好模型之后,接下來我們要告訴機器,滿足什么樣條件的a和b才是最好的模型,即定義代價函數。
假設測試的數據(x1、y1)、(x2、y2)、(x3、y3)…;
假設測試數據到直線的距離之和為J;
則J²=1/M∑(x-xi)²+(y-yi)²之和,其中xi、yi表示每點的測試數據,M表示測試數據的個數。
因此我們定義最好的就是:使得J的值最小時,就是最好的。
第三步:找出最好的模型
根據第二步,我們知道什么是最好的了,接下來就是想辦法求解出最好的解。
常用的就是梯度下降法,求最小值。剩下的就是輸入數據去訓練了,訓練數據的量和數據源的不同,就會導致最終的參數a、b不一樣。
這三步中基本上就是轉化為數學問題,后面會單獨寫一篇文章說明如何將一個AI模型轉化為數學的求解問題,其中主要涉及的一些專稱有:預測函數、代價函數、誤差、梯度下降、收斂、正則化、反向傳播等等,感興趣的同學可以關注下。
02 監督學習(Supervised Learning)
監督學習是從已標記的訓練數據來推斷一個功能的機器學習任務,主要特點就是訓練數據是有標簽的。
比如說圖像識別:當輸入一張貓的圖片時,你告訴機器這是貓;當輸入一張狗的圖片時,你告訴機器這是狗;如此訓練。

測試時,當你輸入一張機器以前沒見過的照片,機器能辨認出這張圖片是貓還是狗。

監督學習的訓練數據是有標簽的,即輸入時告訴機器這是什么,通過輸入是給定標簽的數據,讓機器自動找出輸入與輸出之間的關系。
其實現在我們看到的人工智能,大多數是監督學習。
監督學習優缺點:
- 優點:算法的難度較低,模型容易訓練;
- 缺點:需要人工給大量的訓練數據打上標簽,因此就催生了數據標簽師和數據訓練師的崗位。
03 線性回歸(Linear Regression)
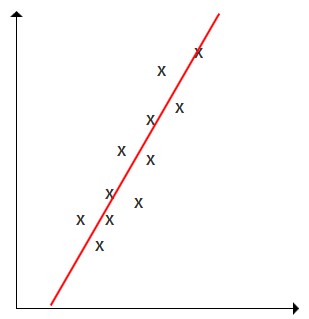
我們前面舉的預測房價的例子就是一個線性回歸的問題,我們要找一條線去擬合這些測試數據,讓誤差最小。
如果我們要誤差最小,即要每一個測試點到直線的距離之和最小。(具體步驟可以參考我們前面介紹的實現機器學習的三個步驟)。
但是在現實問題中,可能房價跟住房面值不是單純的直線關系,當住房面積到一定大的時候,房價的增幅就會變緩了;或者說當數據量不夠大時,我們得到的模型跟測試數據太擬合了,不夠通用。
為了解決這些問題,我們就需要正則化,就是讓模型更加的通用。
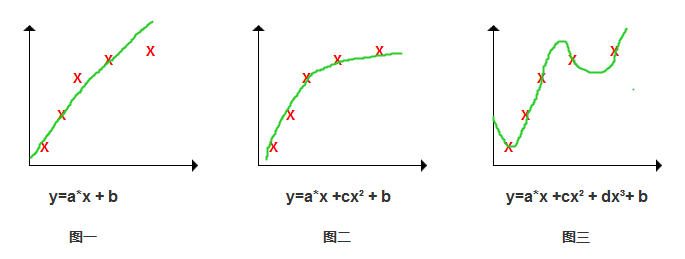
圖一:如果我們按y=a*x+b這個模型去訓練,那得到的就會像圖一這樣的曲線,而當住房面積比較大時,可能預測效果就不好了;
圖二:我們加入了一個二次項,擬合效果就很不錯了,輸入新數據時,預測效果比較好,所以這就是比較好的模;
那這么說就是擬合程度越高越好?并不是,我們的目的不是在訓練數據中找出最擬合的模型,而是找出當輸入新數據時,預測效果最好的。因此,這個模型必須具體通用性。
圖三:我們加入了更高的三次項,模型跟訓練數據擬合度太高,但不具備通用性,當你輸入新數據時,其實預測效果也不好。因此需要通過正則化后,找到比較理想的通用模型。
線性回歸的特點:
- 主要解決連續值預測的問題;
- 輸出的是數值。
04 邏輯回歸(Logistic Regression)
邏輯回歸輸出的特點:
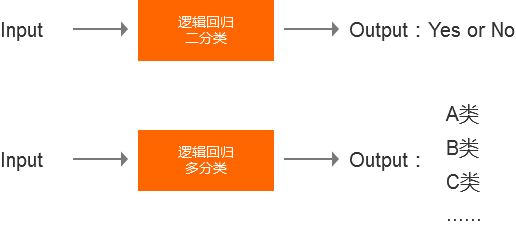
邏輯回歸主要解決的是分類的問題,有二值分類和多分類。
1. 二分類
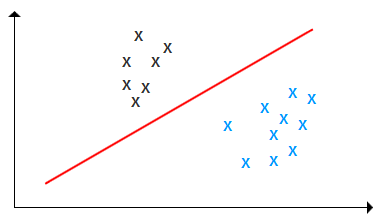
如上圖,我們要做的事情就是找一條線,把黑色的點和藍色的點分開,而不是找一條線去擬合這些點。
比如說做攔截垃圾郵件的模型,就把郵件分為垃圾郵件和非垃圾郵件兩類。輸入一封郵件,經過模型分析,若是垃圾郵件則攔截。
2. 多分類
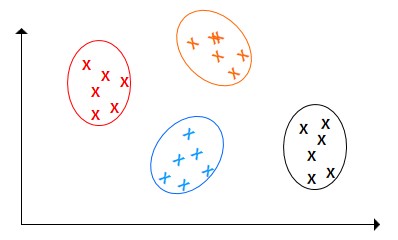
如上圖,要做的是把不同顏色的點各自歸為一類,其實這也是由二分類變換而成的。
比如說讓機器閱讀大量的文章,然后把文章分類。
線性回歸與邏輯回歸的舉例說明,以預測天氣為例:
- 如果要預測明天的溫度,那就是線性回歸問題;
- 如果要預測明天是否下雨,那就是二分類的邏輯回歸問題;
- 如果要預測明天的風級(1級、2級、3級…),那就是多分類的邏輯回歸問題。
05 神經網絡(Neural Networks)
1. 為什么需要神經網絡?
假設我們現在做的是房價是升還是降的分類問題,我們之前假設影響房價的因素只有住房面積,但是實際上可能還需要考慮樓層、建筑時間、地段、售賣時間、朝向、房間的數量等等,可能影響因素是成千上萬的。并且各因素之間可能存在關聯關系的。
如果用回歸問題解,則設置函數:
y=(a1*X1 + a2*X2 + a3*X3 + a4*X4…)+=(b1*X1X2 + b2*X1*X3 + b3*X1X4 …)+(三次項的組合)+(n次項的組合)
普通回歸模型:
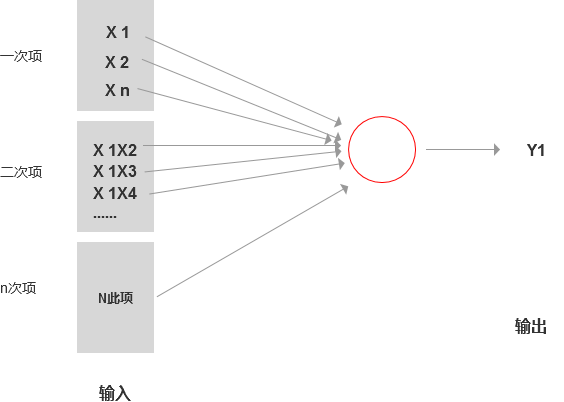
對于該模型來說,每個特征變量的之間的相互組合(二次項或三次項)都變成新的特征變量,那么每多一個高次項時,特征變量就會數量級的變大,當特征變量大于是數千個的時候,用回歸算法就很慢了。而我們轉換為神經網絡去求解,就會簡單得多。
神經網絡模型:
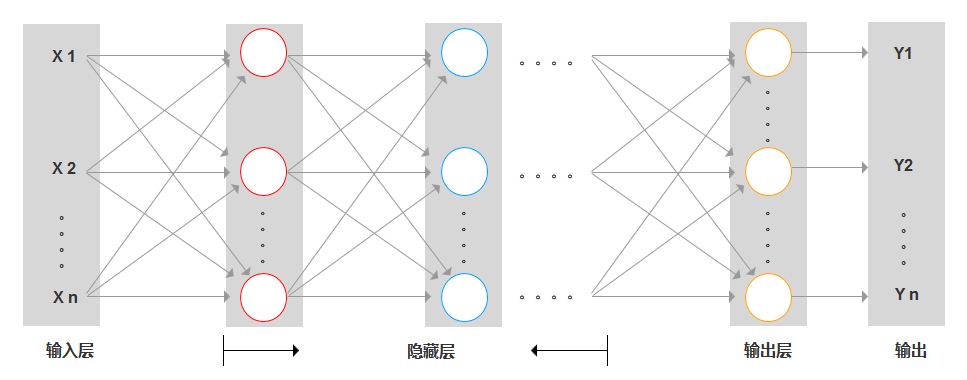
2. 為什么叫做神經網絡?
先看下人類神經元的鏈接方式:
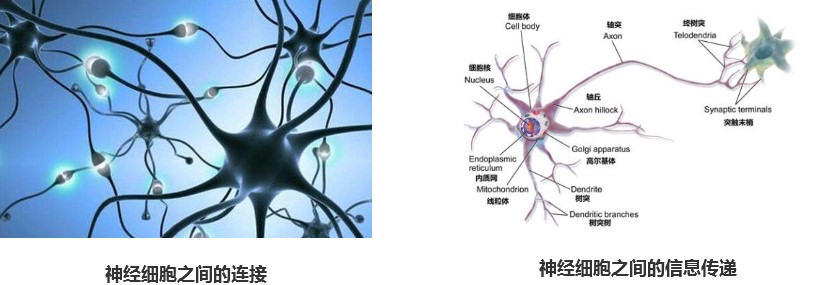
人的神經細胞連接是錯綜復雜的,一個神經元接受到多個神經元的信息,經過對信息處理后,再把信息傳遞給下一個神經元。
神經網絡的設計靈感就是來源于神經細胞之間的信息傳遞,我們可以把神經網絡中的每個圓圈看成是一個神經元,它接受上一級網絡的輸入,經過處理后,再把信息傳遞給下一級網絡。
3. 為什么要模擬人類的神經網絡?人類的神經網絡有什么神奇的地方?
神經系統科學家做過一個有趣的實驗,把一個動物的聽覺皮層切下來,移植到另一個動物的大腦上,替換其視覺皮層,這樣從眼睛收到的信號將傳遞給移植過來的聽覺皮層,最后的結果表明這個移植過來的聽覺皮層也學會了“看”。
還有很多有趣的實驗:
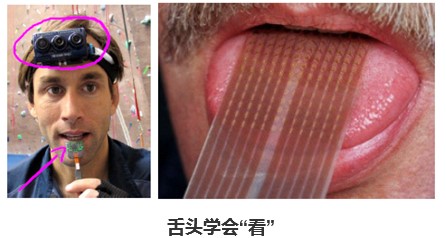
上圖是用舌頭學會“看”的一個例子,它能幫助失明人士看見事物。
它的原理是在前額上帶一個灰度攝像頭,攝像頭能獲取你面前事物的低分辨率的灰度圖像。再連一根線到安裝了電極陣列的舌頭上,那么每個像素都被映射到你舌頭的某個位置上。電壓值高的點對應一個暗像素,電壓值低的點對應于亮像素,這樣舌頭通過感受電壓的高度來處理分辨率,從而學會了“看”。
因此,這說明了動物神經網絡的學習能力有多驚人。也就是說你把感器的信號接入到大腦中,大腦的學習算法就能找出學習數據的方法并處理這些數據。
從某種意義上來說如果我們能找出大腦的學習算法,然后在計算機上執行大腦學習算法或與之相似的算法,這就是我們要機器模擬人的原因。
4. 神經網絡跟深度學習之間有什么關系?
1)相同:
都采用了分層結構(輸入層、隱藏層、輸出層)的多層神經結構。
2)不同:
- 層數不同,通常層數比較高的我們叫做深度學習,但具體多少層算高,目前也沒有有個統一的定義,有人說10層,有人說20層;
- 訓練機制不同,本質上的區別還是訓練機制的不同。
傳統的神經網絡采用的是back propagation的方式進行,這種機制對于7層以上的網絡,殘差傳播到最前面就變得很小了,所謂的梯度擴散。
而深度學習采用的訓練方法分兩步,第一步是逐層訓練,第二步是調優。
深度學習中,最出名的就是卷積神經網絡(CNN)和循環神經網絡(RNN)。
關于深度學習,在這里就不展開了,之后會單獨寫一篇文章討論深度學習,感興趣的同學可以關注下。
06 半監督學習(Semi-supervised Learning)
半監督學習主要特點是在訓練數據中,有小部分數據是有標簽,而大部分數據是無標簽的。
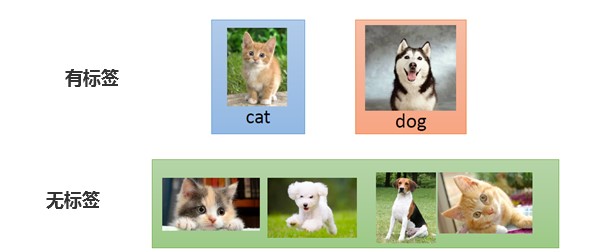
半監督學習更加像人的學習方式,就像小時候,媽媽告訴你這是雞,這是鴨,這是狗,但她不能帶你見過這個世界上所有的生物;下次見到天上飛的,你可能會猜這是一只鳥,雖然你不知道具體這只鳥叫什么名字。
其實我們不缺數據,缺的是有多樣標簽的數據。因為你要想數據很簡單,就放一個攝像頭不斷拍,放一個錄音機不斷錄,就有大量數據了。
簡單說一個半監督學習的方式:
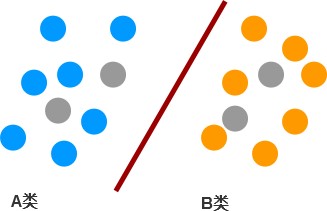
假設藍色的和黃色的是有標簽的兩類數據,而灰色的是無標簽的數據,那么我們先根據藍色和黃色的數據劃了分類,然后看灰色的數據在哪邊,再給灰色的數據分別標上藍色或黃色的標簽。
所以半監督學習的一個重要思想就是:怎么用有標簽的數據去幫助無標簽的數據去打上標簽。
07 無監督學習(Unsupervised Learning)
無監督學習的主要特點是訓練數據是無標簽的,需要通過大量的數據訓練,讓機器自主總結出這些數據的結構和特點。
就像一個不懂得欣賞畫的人去看畫展,看完之后,他可以憑感覺歸納出這是一類風格,另外的這些是另一種風格,但他不知道原來這是寫實派,那些是印象派。
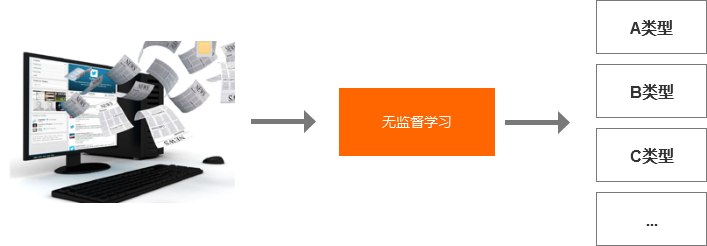
比如說給機器看大量的文章,機器就學會把文章分類,但他并不知道這個是經濟類的、文學類的、軍事類的等等,機器并不知道每一類是什么,它只知道把相似的歸到一類。
無監督學習主要在解決分類和聚類問題方面的應用比較典型,比如說Googel和頭條的內容分類。
08 強化學習(Reinforcement Learning)
先來聊聊強化學習跟監督學習有什么不同。

監督學習是每輸入一個訓練數據,就會告訴機器人結果。就像有老師手把手在教你,你每做一道題老師都會告訴你對錯和原因。
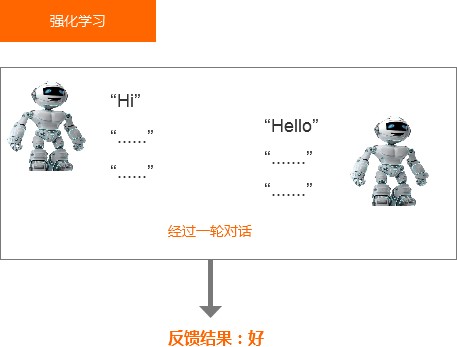
強化學習是進行完一輪對話之后,才會跟機器人說這一輪對話好還是壞,具體是語氣不對,還是回答錯誤,還是聲音太小,機器不知道,它只知道結果是不好的。就像你高考,沒有老師在你身邊告訴你每做的一道題是對或錯吧,最終你只會得到一個結果:得了多少分。
強化學習模型:
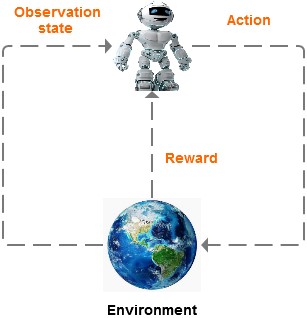
首先機器會觀察它所處的環境,然后做出行動;機器的行動會改變環境;接著機器再次觀察環境,再次做出行動,如此循環。
每一次訓練結束,機器都會收到一個回饋,機器根據回饋,不斷調整模型。
以Alpha Go為例:
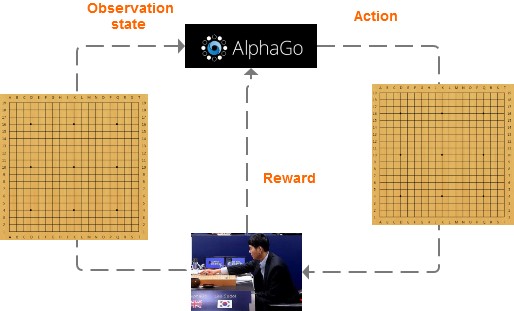
首先AlphaGo會觀察棋盤的情況,然后決定下一步落子;待對方落子后,AlphaGo再次根據棋盤的情況再次進行下一步。直到分出勝負之后,AlphaGo得到的reward是贏或輸。經過這樣大量的訓練之后,AlphaGo就學會了,怎樣做才更有可能贏。
強化訓練的特點:
- 反饋機制,根據反饋不斷調整自己的策略;
- 反饋有延遲,不是每次動作都會得到反饋;比如說AlphaGo,不是每一次落子都會有反饋,而是下完一整盤才得到勝負的反饋。
在此就介紹完了機器學習常見的內容,若文中有不恰當的地方,歡迎各路大神批評指正。
本文由 @Jimmy 原創發布于人人都是產品經理。未經許可,禁止轉載。
題圖來自Unsplash,基于CC0協議。