
筆者在學習Tom Tullis、Bill Albert的《用戶體驗度量》后,開始思考:針對B端產品,如何在線上環境中,通過對用戶數據的采集、分析,完成對產品的用戶體驗量化?
本文給出三個案例進行嘗試,從簡單到復雜闡述三種量化的維度。

為什么要量化用戶體驗
針對企業內部使用的B端產品,在日常做設計的過程中,體驗設計師常常是憑借經驗來完成對產品的體驗優化。“經驗”一般有兩種來源:
- 參考競品的設計
- 參考自己已做過的類似產品
很明顯,這兩種設計經驗有一個很大的缺陷,就是很容易“拍腦袋”定方案——產品經理拍、設計師拍,更多的時候是領導拍。
“拍腦袋”,有時真的是天才般的靈感火花,但大概率是盲目瞎拍。因此,如何避免出現這種“瞎拍”,是體驗設計師應該考慮一下的問題。“用戶體驗量化”就是一個很好的手段:
“通過對用戶體驗相關的數據進行采集、分析,使用量化的數據證明設計的‘合適’與‘不合適’,合適的保留、不合適的繼續優化,為產品的迭代建設保駕護航”
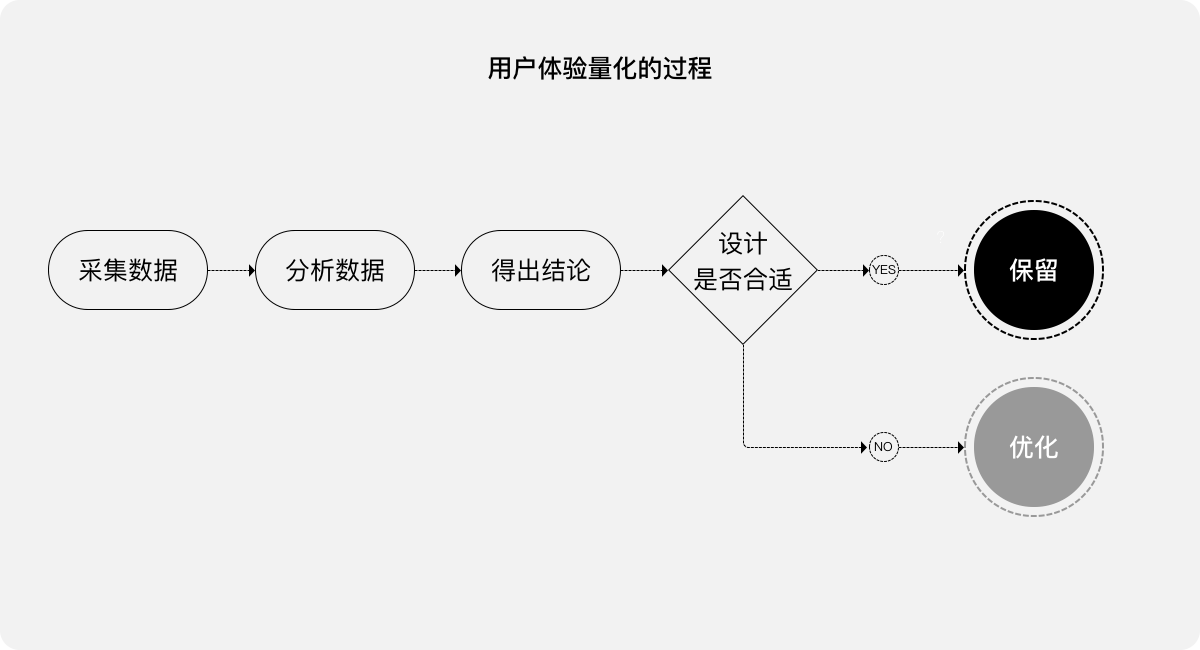
一維量化:單個指標直接比較
案例一:“任務”
針對B端效率類的工具型產品,其不以用戶留存時間為目標,反而如果能降低用戶完成任務的耗時,則說明該任務鏈路的用戶體驗優化是成功的。
因此,線上可以采集一個指標的數據:任務時長,即用戶從啟動任務到任務完成所用的時長。或者,直接采集用戶從進入該B端效率類的工具型產品到最終離開的時長。通過比較優化前后的時長,以達到用戶體驗量化的目的。
但是該類型產品所采集的數據存在一種缺陷——樣本量少。
原因在于這種產品在公司內部的用戶群體很小,例如一些基礎類的云產品,用戶量可能在兩位數。因此,采集的數據其分布狀態離散、無法直接通過分布狀態判定。
那么如何在有限的樣本量情況下,區分其優化前后的用戶體驗數據呢?
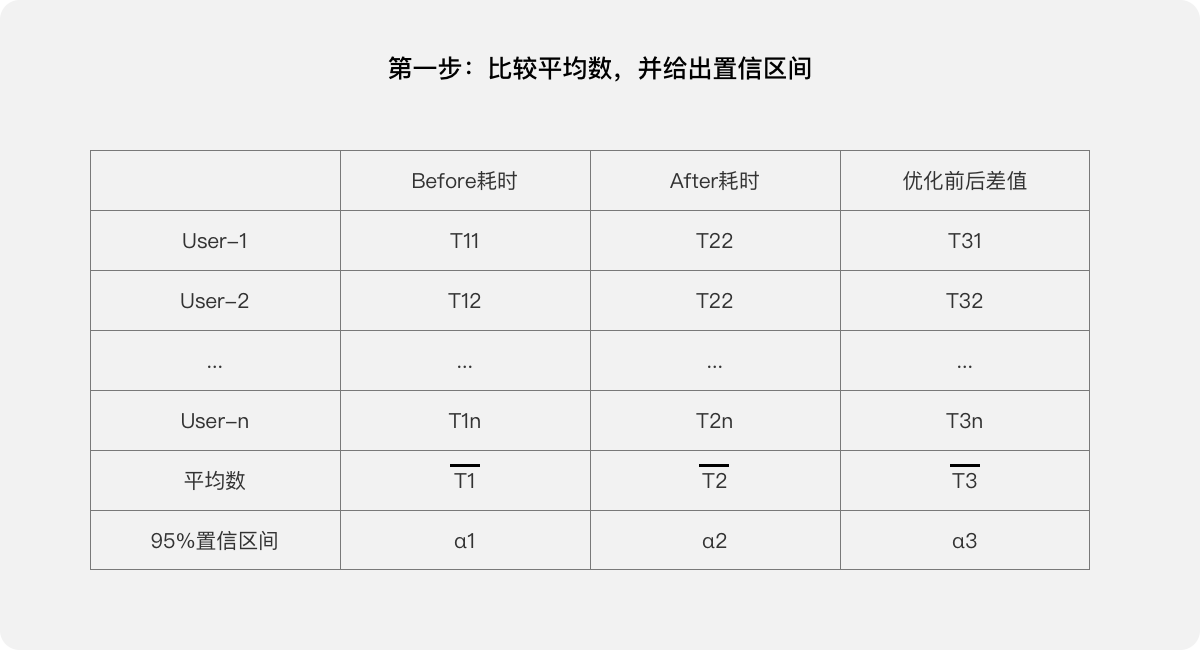
我們可以進行數據分析:平均數,置信區間,t檢驗。

第一步,比較平均數,并給出置信區間。
第二步,判斷置信區間是否存在重疊,如果“無重疊”或“重疊較小”,則基本認定差異顯著,也就可以直接通過優化前后差值及其置信區間來量化用戶體驗,參考第五步。
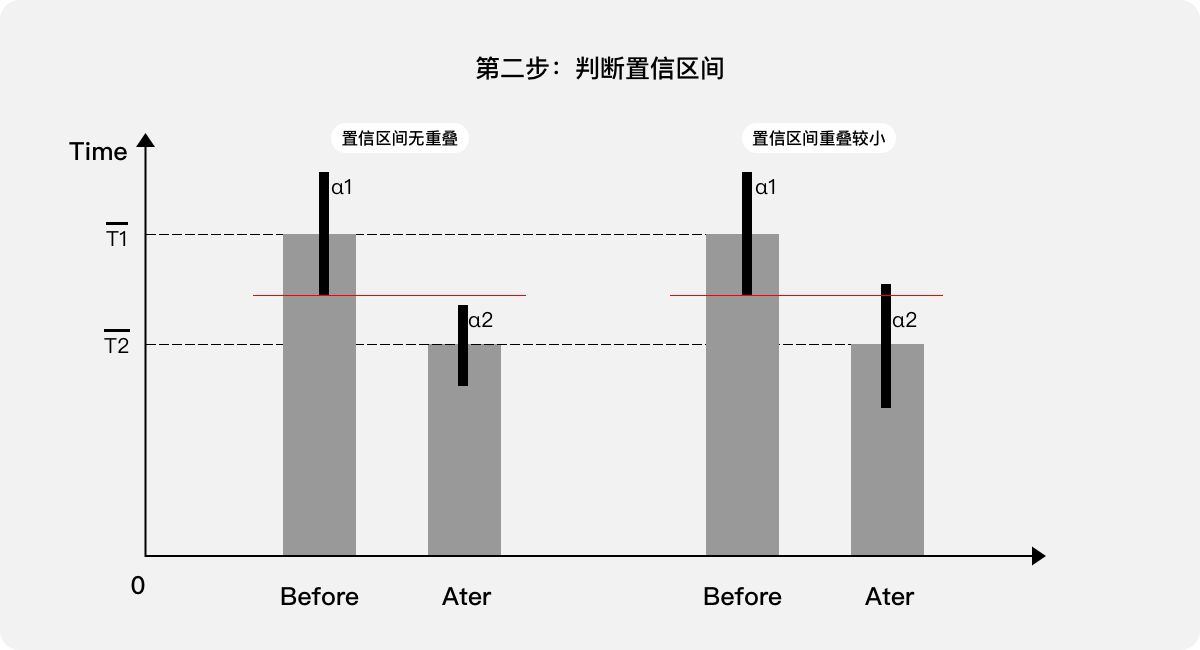
第三步,如果置信區間“重疊較大”,則無法確認存在差異,需進行t檢驗,如果t檢驗的概率值較大(>0.05)則說明差異性不顯著,表示優化前后的用戶體驗變化不明顯:優化方案“不合適”。
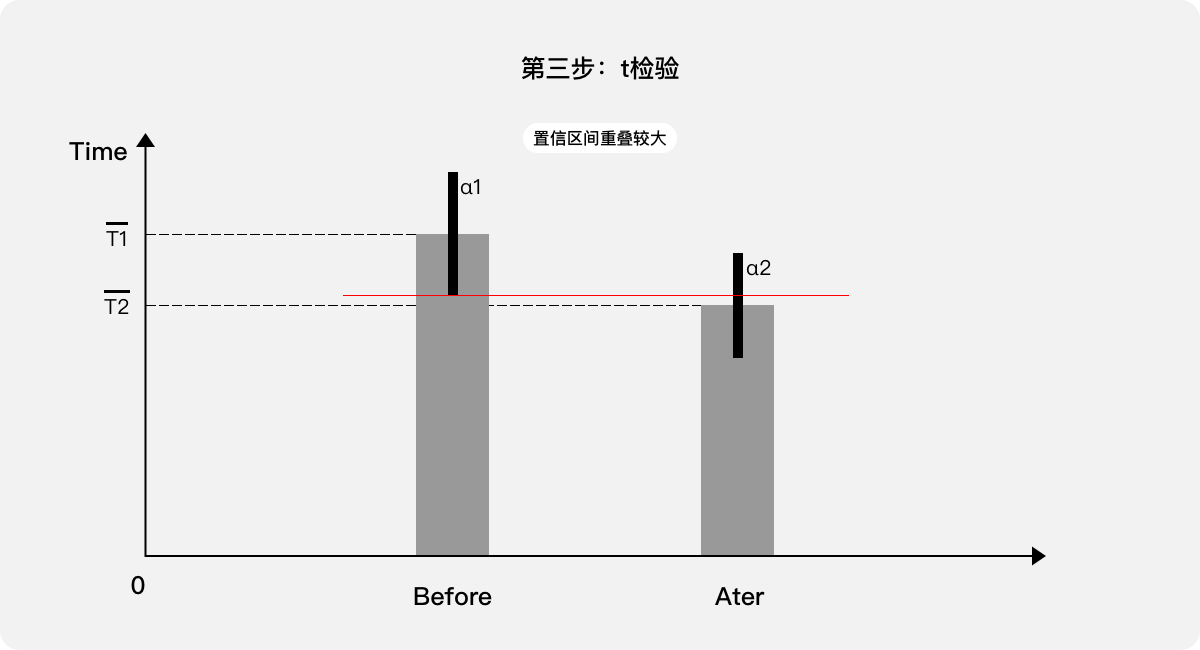
第四步,如果t檢驗的概率值很小(<<0.05)說明差異性顯著,表示優化前后的用戶體驗變化明顯,也就可以直接通過優化前后的差值及其置信區間來量化用戶體驗。
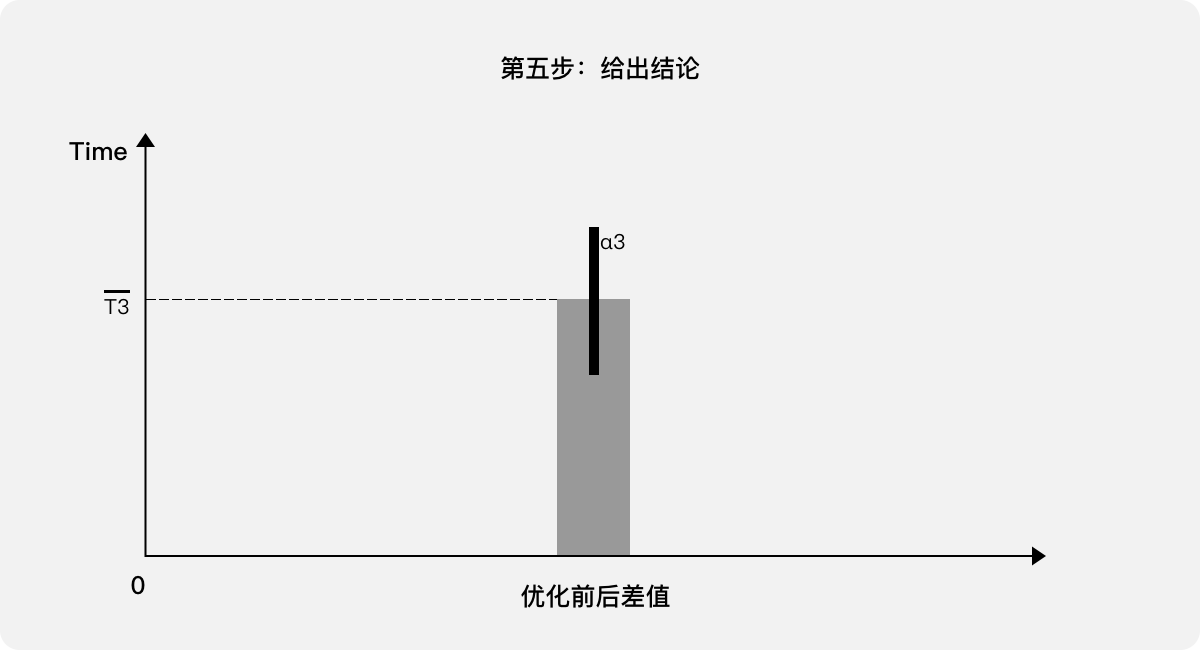
第五步,給出結論:該“任務”經過用戶體驗優化,成功降低了單次“任務”耗時。在95%的置信區間內平均降低了T3,其中置信區間為(T3-α3,T3+α3)。
二維量化:多個指標進行比較
案例二:“表單”
針對B端產品的某個“表單”頁面,在用戶填寫過程中采集兩個指標的數據:
- 耗時:用戶從打開表單填寫頁面到成功提交所用的時長
- 報錯次數:用戶在填寫過程中觸發報錯提示的總次數
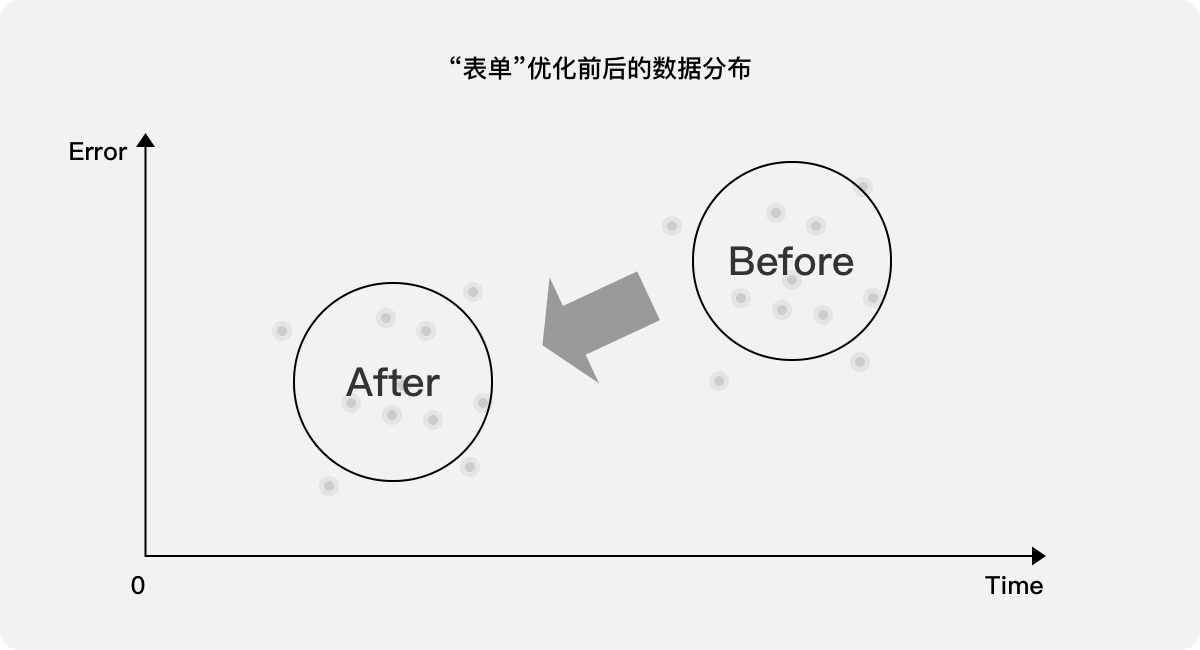
當體驗設計師優化該表單填寫頁面并發布上線后,比較前后版本的耗時和報錯次數,并將其映射至二維圖,理想態應該是整體數據向左下移動,優化前耗時長、報錯次數多,優化后耗時短、報錯次數少。
發散點1:如果表單有多個頁面,可分別從整體和單個頁面去進行量化分析,以發現鏈路的哪個環節仍然存在問題。

發散點2:針對報錯的內容,將其進行等級區分,可更細致量化分析,甚至可用低等級異常置換高等級異常,以提升整體體驗。
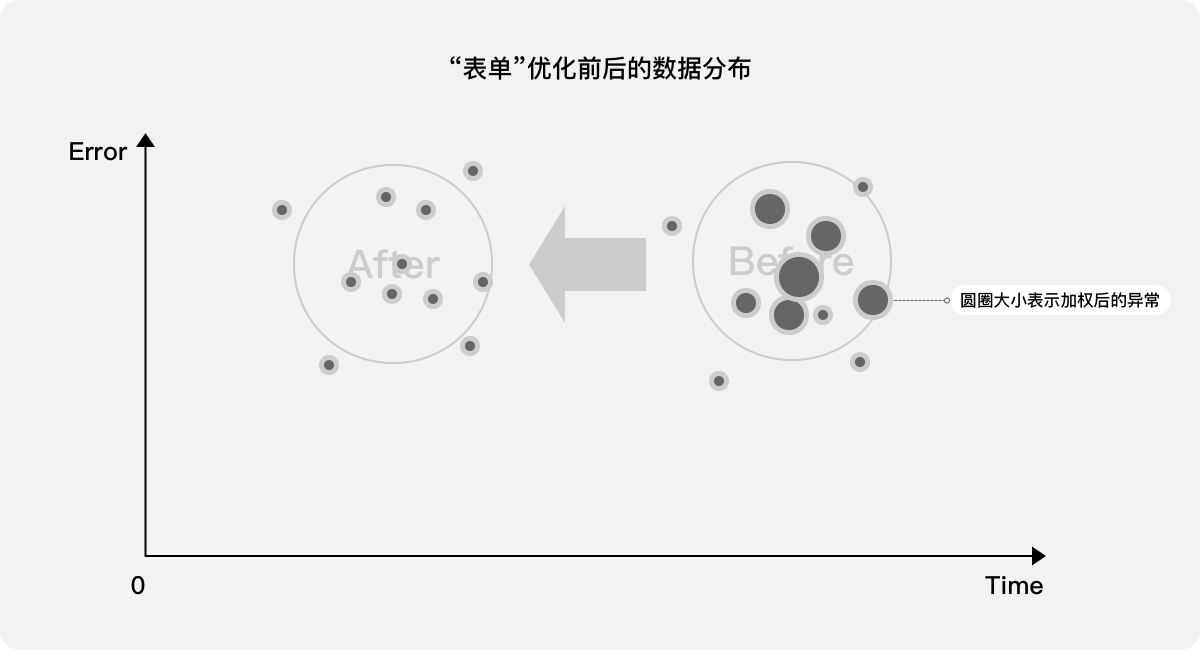
如上,當只需分析兩項指標的時候,可以直接將數據映射在二維圖上進行比較。但如果有3個及以上的指標,如何進行量化?
可以通過給指標進行“加權”,計算出一個綜合分值,通過比較綜合分值就可以間接量化其用戶體驗。
假設有三項指標:p、q、r
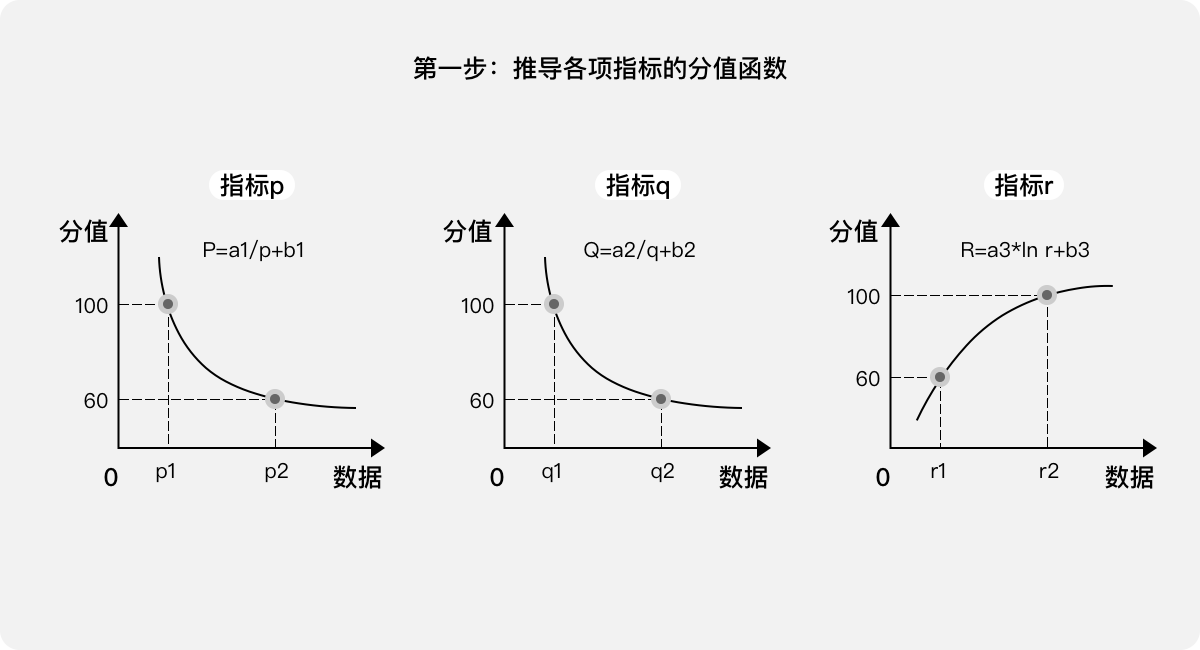
第一步:推導各項指標的分值函數(分數越高表示體驗越好)。
建議:如果指標的數據和得分是正相關,可以使用對數函數(y=ln x);如果是負相關,則可以使用冪函數(y=1/x)。通過定義“滿分、及格”兩個坐標(如果需要更細膩,甚至可以定義多個坐標,例如優良中差等等),即可推導出各項指標的函數式(a、b均為系數)。
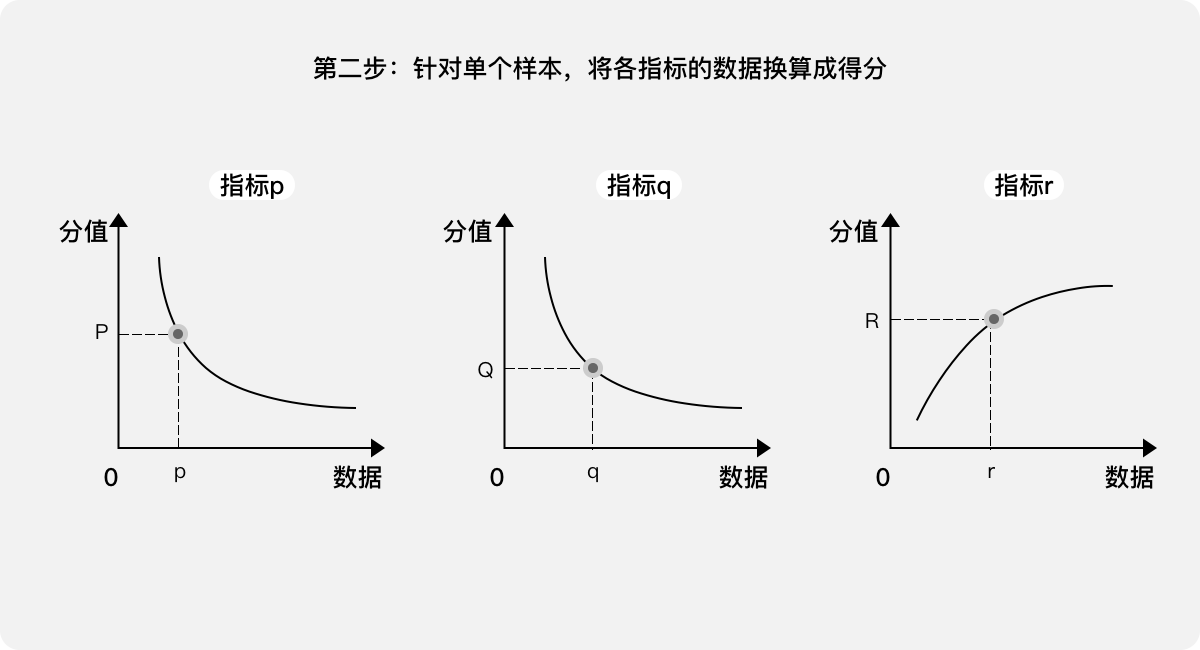
第二步:針對單個樣本,將各指標的數據換算成分值。把各項指標的采集數據當作自變量,可計算得出對應的因變量,即得分:P、Q、R。
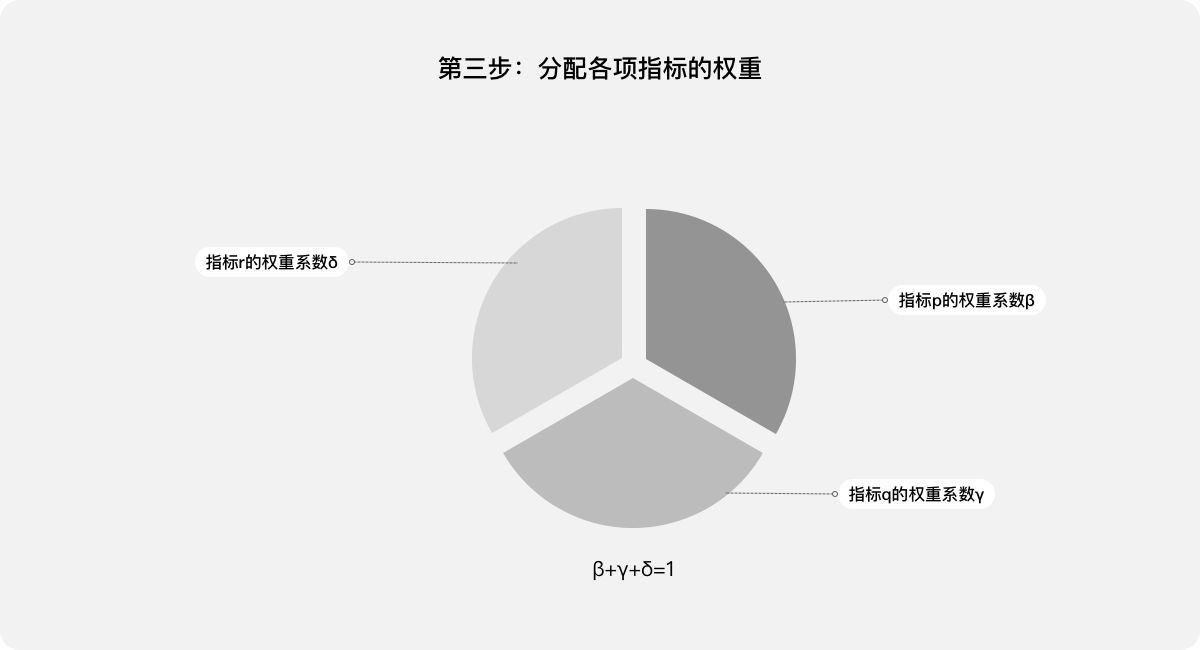
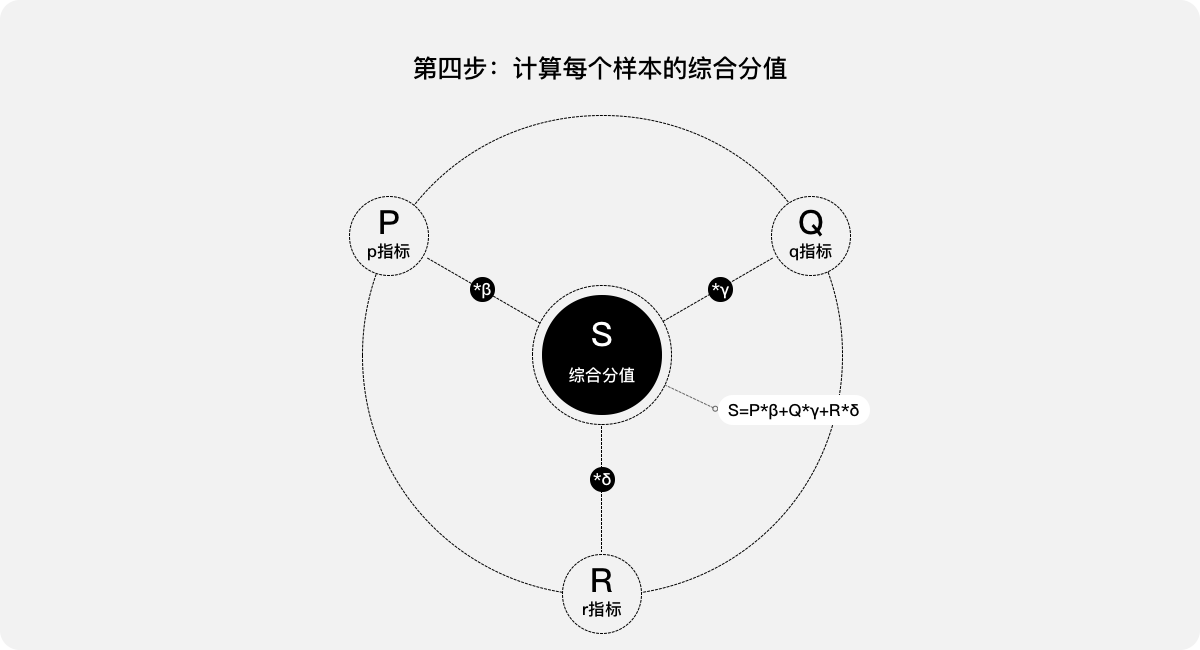
第三步:分配各項指標的權重:β、γ、δ,其中β+γ+δ=1。
第四步:計算每個樣本的綜合分值。其綜合分值等于每項指標的得分與權重的乘積之和,為:
S=P*β+Q*γ+R*δ
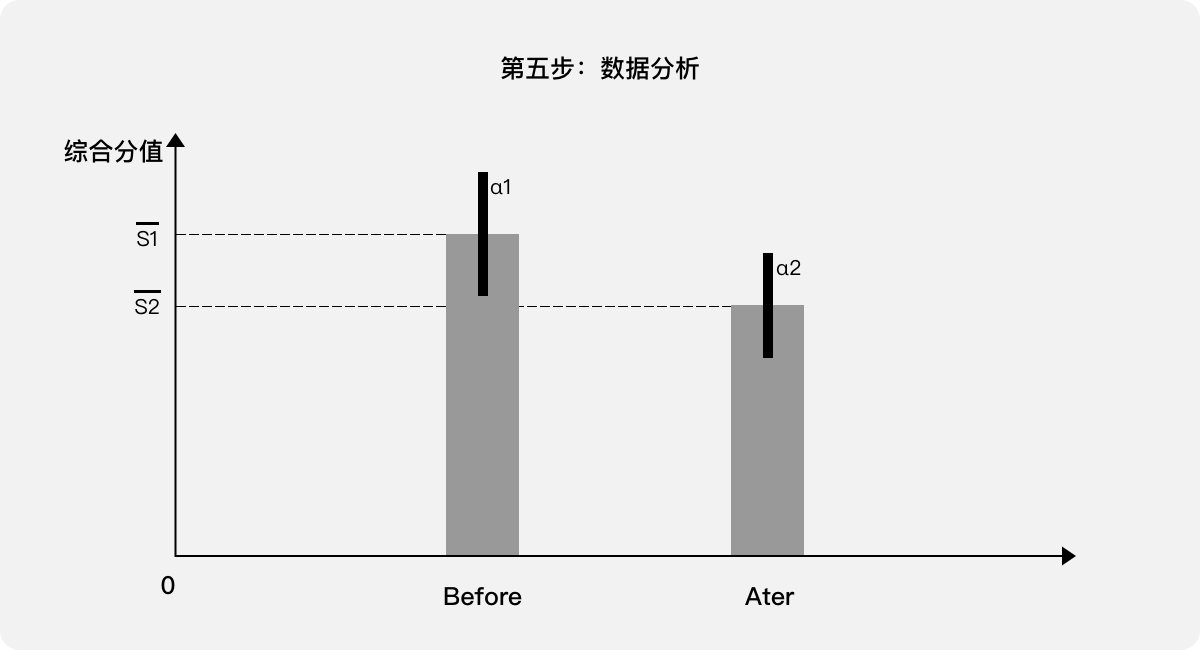
第五步:數據分析。針對所有用戶的綜合分值S,參考使用案例一中的“平均數、置信區間、t檢驗”進行分析,比較優化前后的數據。
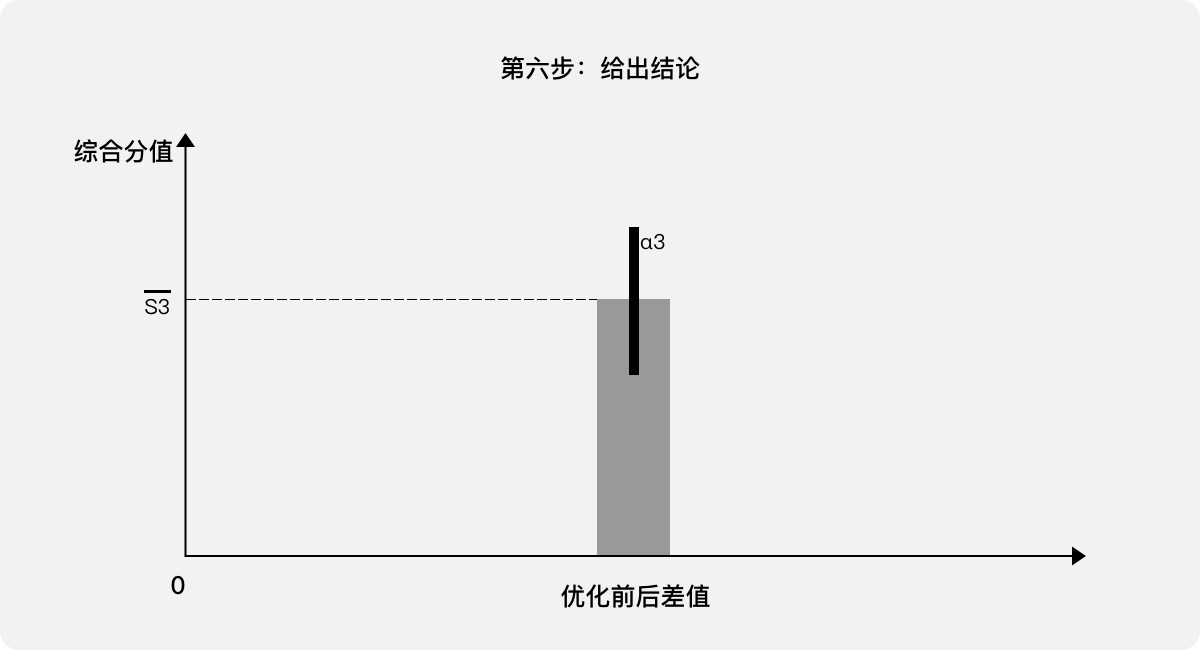
第六步:給出結論。該“表單”經過用戶體驗優化,成功提高了用戶體驗分值。在95%的置信區間內平均提高了S3,其中置信區間為(S3-α3,S3+α3)。
多維量化:多類指標進行比較
案例三:“產品”
針對B端產品,在量化其整體的用戶體驗時,會采集多種類型的指標,包括不限于:績效、可用性、滿意度、生理數據等等。如何使用多類型指標進行用戶體驗量化?
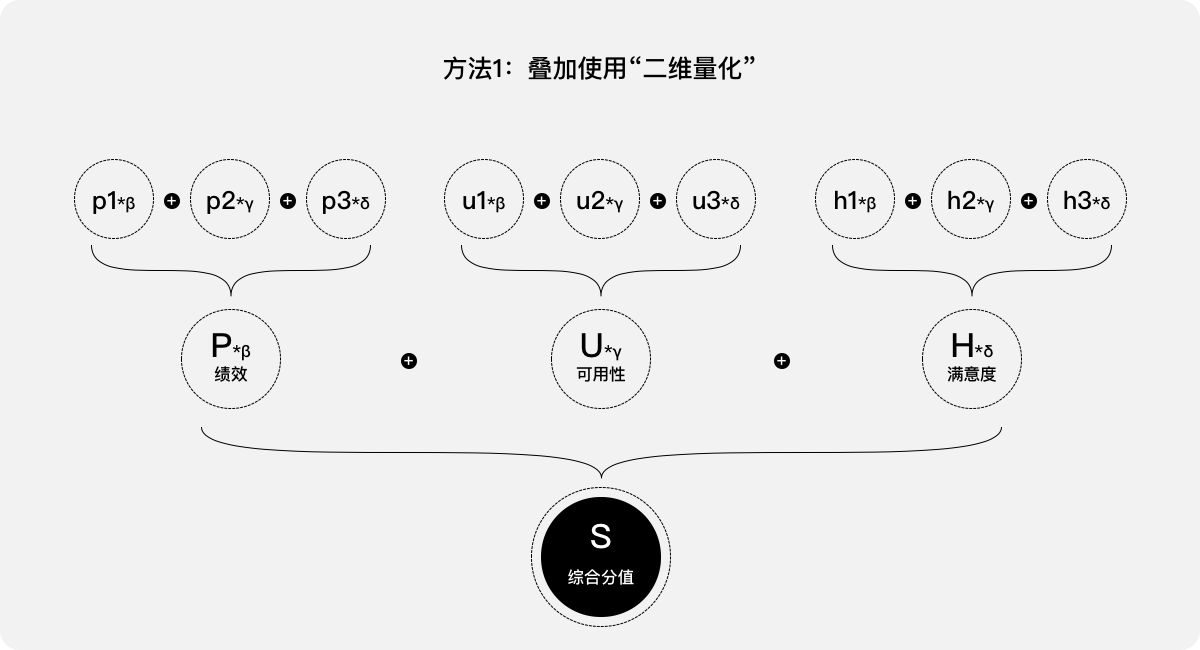
假設采集了以下3類共9種指標的數據:
- 績效,p1、p2、p3
- 可用性,u1、u2、u3
- 滿意度,h1、h2、h3
有兩種方法可以對其進行處理:
方法1:疊加使用“二維量化”。針對“績效”的指標p1、p2、p3,參考案例二中的處理方法予以加權,就可以得出一個“績效”的分值P,同理可分別得出“可用性”的分值U和“滿意度”的分值H;針對這三項分值P、U、H,繼續參考案例二中的處理方法,可以得出一個綜合分值S,即該產品的用戶體驗分值;
方法2:先“降維”,然后使用“二維量化”。將9種指標視為產品的9個維度,首先通過使用降維方法,得到9個互相獨立、具有正交特征的新指標(綜合指標)。然后選出靠前的n個(n<=9)綜合指標,參考案例二中的處理方法予以加權,就可以得出一個綜合分值S,即該產品的用戶體驗分值。
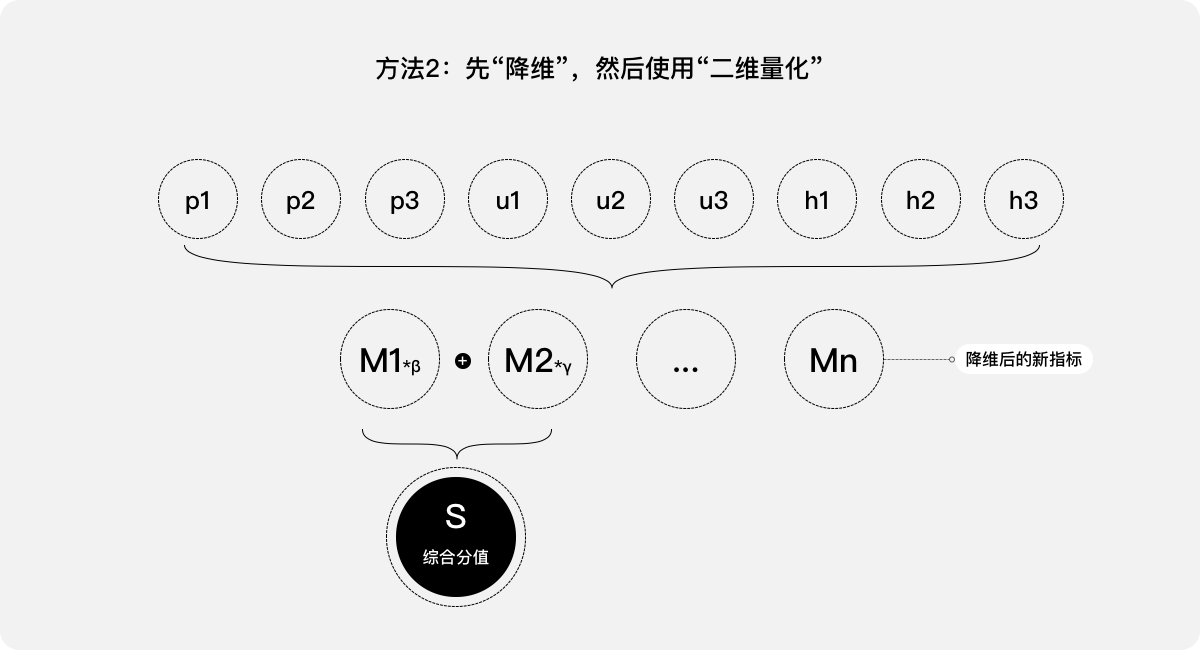
以上兩種方法均可,但第2種可能會更精準、更直觀。
原因在于,雖然指標都是獨立采集、甚至分屬于不同的類型,但部分指標之間可能存在一定的正相關或負相關。例如,績效指標“成功率”和可用性指標“幫助的實時性”可能會存在正相關:幫助的實時性越高,成功率可能會越高。
如果使用方法1進行處理,由于給各指標加權需要人為識別、決定,具有相關性的指標之間其權重難以保持一致。多次人為加權,不僅計算的復雜程度高、穩定性也很低。
如果使用方法2中的降維:
- 對具有相關性的指標進行合并、減少冗余信息造成的誤差
- 去除噪聲和不重要的特征,降維得到的綜合指標之間獨立性強、識別度高。
需要注意的是,降維肯定會損失一些信息,這可能會讓最終結果不能100%體現原數據,但是通過把多維數據降至2、3維,就可以對其進行數據可視化,便于直觀地發現分布形態。針對合并后的綜合指標,人為識別、加權更精準。
降維方法有很多種,此處使用主成分分析法(PrincipalComponents Analysis,PCA)進行降維,其主要是通過對協方差矩陣進行特征分解,以得出數據的主成分(即特征向量)與它們的權值(即特征值),步驟如下:
第一步:選取10個樣本(優化前后各5個),參考案例二種的分值函數分別計算9個維度的分值:p1、p2、p3、u1、u2、u3、h1、h2、h3。
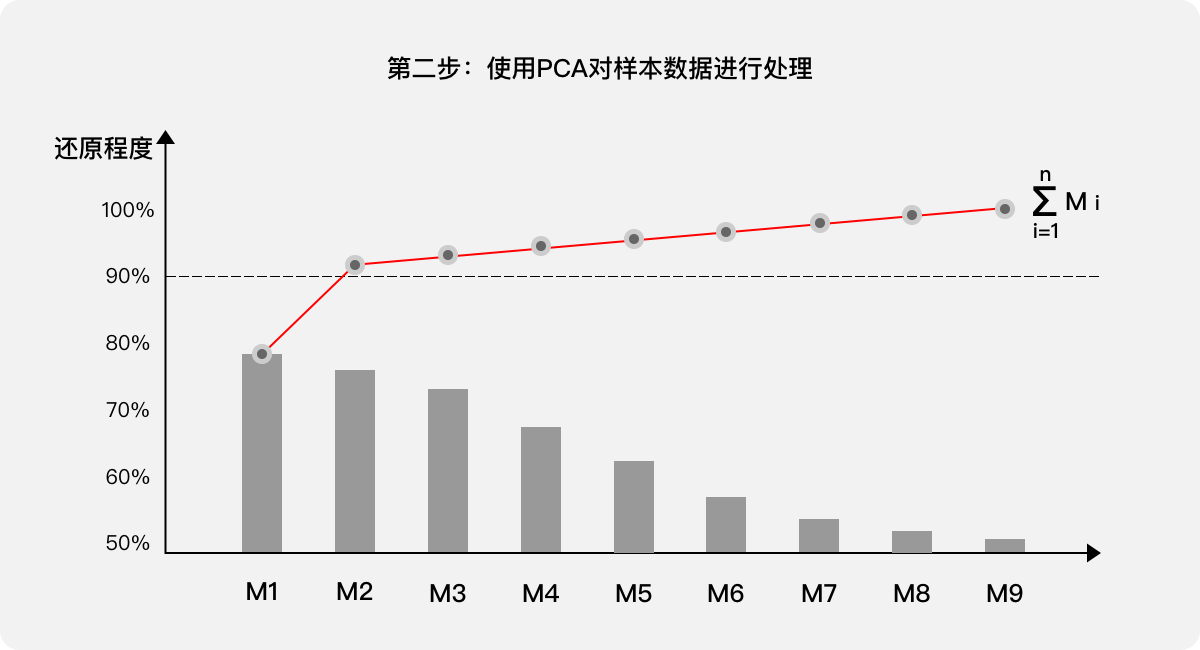
第二步:使用PCA對樣本的數據進行處理,針對處理結果按照還原程度由高到低列出主成分(新的綜合指標M1、M2、M3…M9),根據需求確定合適的還原程度,如果需要90%,則新的綜合指標為M1、M2。
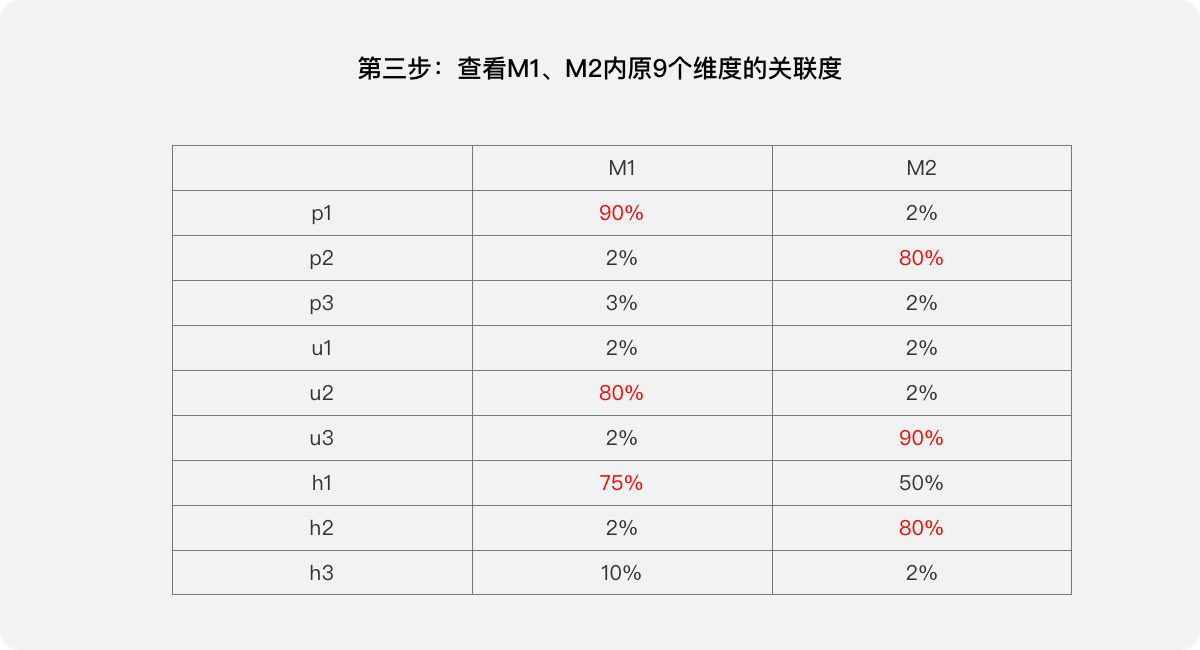
第三步:查看M1、M2內原9個維度的關聯度,據此可理解M1、M2兩個綜合指標的含義,M1主要代表p1、u2、h1,M2主要代表p2、u3、h2。
第四步:數據可視化。針對10個樣本,利用各樣本在M1、M2兩個新的綜合指標內的分值(坐標),映射至二維圖。
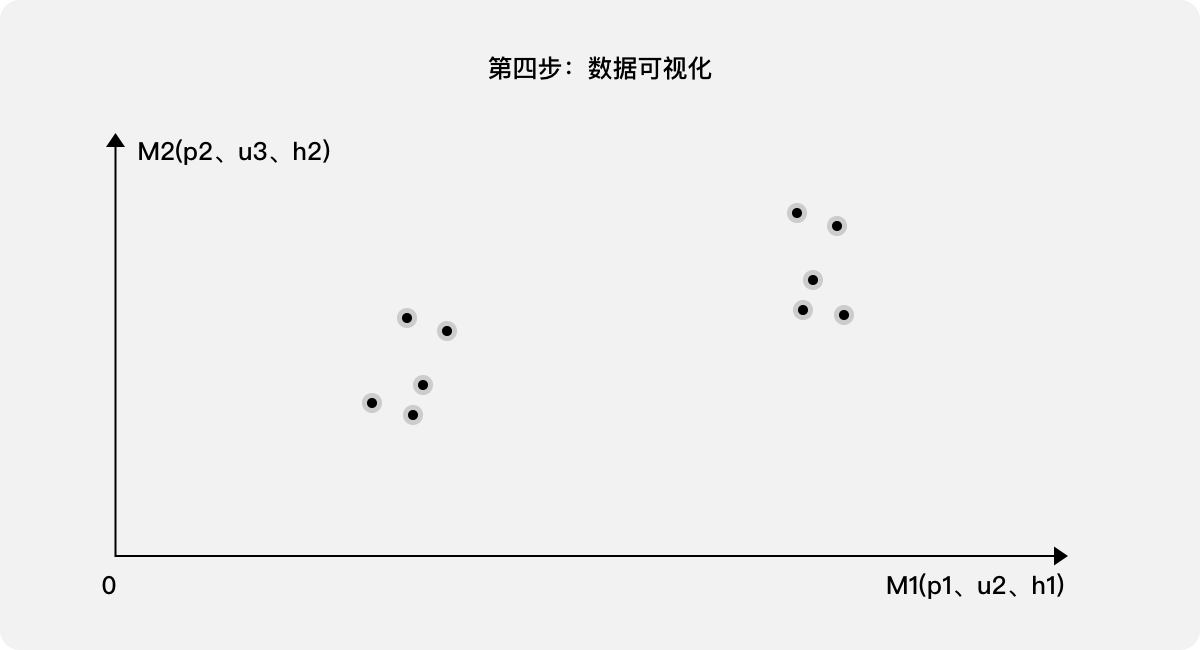
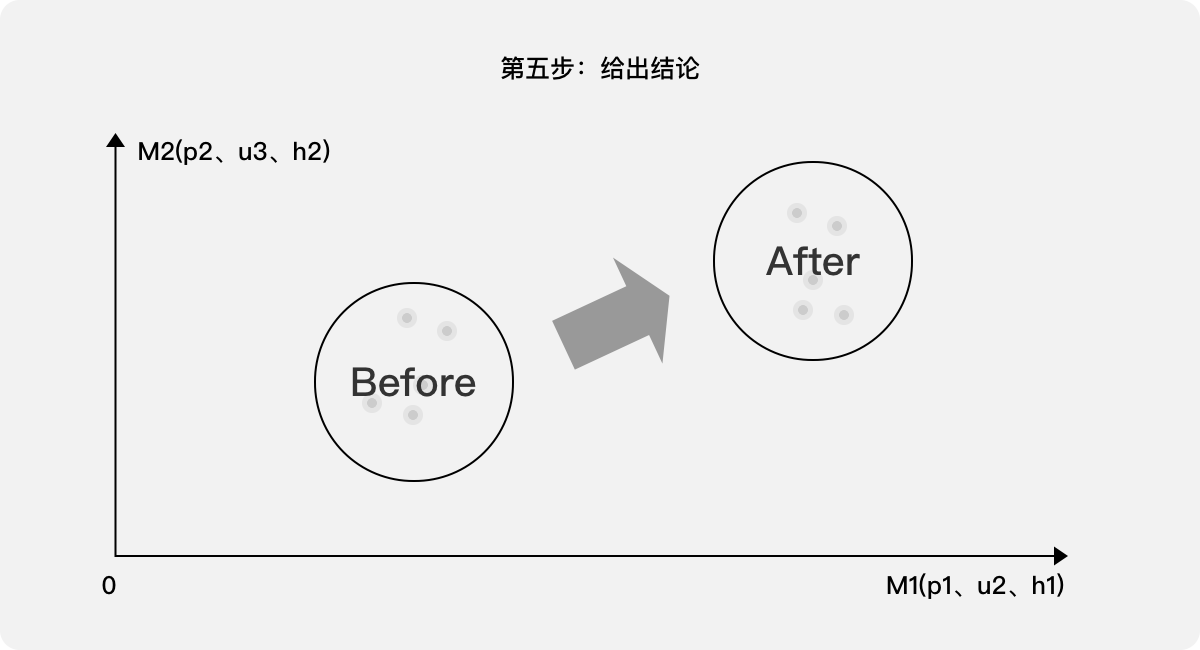
第五步:給出結論。通過觀察10個樣本的分布狀態,可以清晰看出經過優化,產品的用戶體驗分值是否明顯提高。另,如果需要得出一個綜合分值S,則可以根據M1、M2的含義分別予以加權,參考案例二中的處理方法即可得出。
總結
由于B端產品的用戶群體較小、強功能、弱設計等等原因,一般在產品的整個生命周期里面都很少使用量化的數據來指導產品建設和體驗設計。在本文中,通過三個案例介紹了三種量化方案:
- 第一個“任務”案例中,是量化單個指標,定義為“一維量化”
- 第二個“表單”案例中,是量化多個指標,定義為“二維量化”
- 第三個“產品”案例中,是量化多類指標(降維),定義為“多維量化”
不同類型、不同建設階段的B端產品,可以選擇合適的用戶體驗量化方案。尋求量化點并采集有效數據,是用戶體驗設計師可以多多思考的。
作者:胡欣欣,公眾號:吹拉彈唱大師(ID:cltcds)
本文由@吹拉彈唱大師 原創發布于人人都是產品經理,未經許可,禁止轉載。
題圖來自Unsplash, 基于CC0協議