
編輯導語:推薦策略產品的必備技能之一:推薦系統框架,可能有的同學還不太了解,作者簡單地分享了一些相關知識,我們一起來看一下。

本模塊的目標:
- 了解推薦系統框架,以及這套架構的演進
- 了解推薦系統框架中的各個模塊的功能
- 了解推薦系統的數據流
一、推薦系統架構組成模塊
一個經典的推薦系統的架構,主要包括如下四部分:
- 推薦服務:該服務從服務器獲取推薦請求,然后返回推薦結果。
- 存儲系統:這些系統存儲用戶畫像、物品畫像和模型參數。
- 離線學習(Offline learning):該組件從用戶行為數據中學習模型參數,然后按照一定的周期將參數更新后的模型推送到在線存儲系統中;物品畫像學習;用戶畫像學習。
- 在線學習(Online learning):實時更新模型。
1. 推薦服務
“推薦服務”的功能是對來自業務的request進行預測。
比如,我這會打開抖音,抖音后臺會發送一個request給推薦服務所在的服務器,服務器接收到這個request之后,會根據過去我在抖音上的行為偏好,為我推薦我可能感興趣的短視頻。
2. 存儲系統
“存儲系統”的功能是存儲用戶畫像、物品畫像、以及模型參數。
3. 離線學習
“離線學習”的功能包括:模型訓練、物品畫像、用戶畫像計算。
- 模型訓練是指給定用戶和物品,以及用戶對該物品的響應數據,來訓練模型參數,這個過程一般需要耗費好幾個小時的時間。
- 物品特征是比如對于非結構化數據,經常需要對這些數據進行TF_IDF計算,這個也是在離線層進行。
- 用戶特征也是。
4. 在線學習
“在線學習”的功能是利用用戶的即時數據進行預估。
二、經典的推薦系統架構
每研究任意一款產品,我第一個想法,都是去看看世界上經典、優秀的產品他們是怎么設計的,以及為什么要這樣設計。我的關注目標很簡單:
- 這套架構的設計目標是什么?
- 為什么是這些目標?
從目標開始,以終為始,同時know how。
know- how(或know- how,或程序性知識)是一個關于如何完成某事的實踐知識的術語,相對于“know-what”(事實)、“know-why”(科學)或“know who”(溝通)。
為了支撐這個目標,creator都做了哪些設計?是否存在好的「設計模式」值得我學習?
設計模式是我嘗試通過學習行業經典的產品,從而發掘出可復用的知識結構。
這類復雜產品設計師是如何做到快速深入業務,做到設計驅動,達到業務與專業雙成長,是否存在好的「設計工作模式」、「設計思維」值得我學習?
業務專業雙成長:雙成長指的就是如何在消耗大量時間深入業務的同時,在專業深度上也能保持精進。
1. 為什么選擇Netfix的推薦系統架構
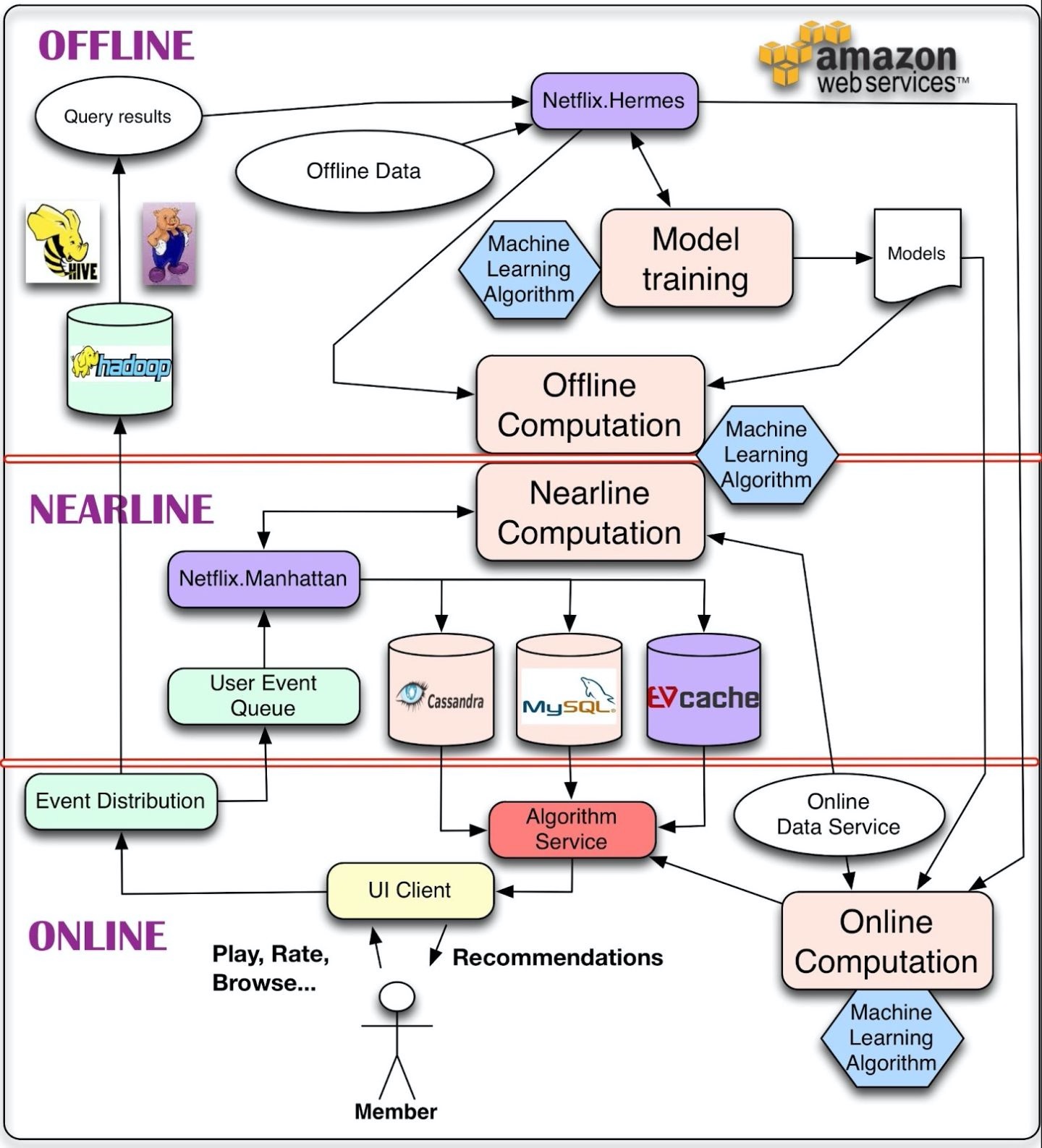
這是Netflix的推薦系統架構,分為離線、近線和在線層。這樣的設計模式,在當前依然是主流模式。
2. Netflix的設計目標是什么?
這是Netflix的推薦系統架構,這個架構的設計目標是:
- 支持好的用戶體驗,且能支持新的推薦策略開展實驗。
- 針對用戶的行為,作出快速的響應。
- 能處理海量數據。
《個性化和推薦的系統架構》中提到:
開發一個能夠處理大量現有數據、能夠響應用戶交互并易于試驗新的推薦方法的軟件體系結構并不是一項簡單的任務。
在這個架構中,計算被分為了離線、近線和在線。
計算可以離線進行、近線進行、也可以在線進行。對于用戶產生的最新行為,在線計算能更好地進行反饋,但是在線必須實時進行反饋。
這樣的話,就對算法的計算復雜性有很大的限制,同時,也會限制能處理的數據量。
離線訓練能處理較大的數據量,且不要求必須是實時相應的。
模型的更新一般是離線進行的,在模型的前后兩次更新這個時間窗口中,由于沒有進入新的數據,所以這個模型一直使用的是舊的數據。
對于推薦系統架構最關鍵的因素是如何將在線和離線計算無縫結合。
近線計算是在上述兩者之間,在近線計算,我們可以執行類似在線的計算,但不要求實時響應。
再簡單理解一下離線、近線和在線。
- 離線:不用實時數據,不提供實時服務;
- 近線:使用實時數據,不保證實時服務;
- 在線:使用實時數據,要保證實時服務。
3. 推薦系統的用例
背景設置:這樣一個場景,西藍花資訊問答是一個基于多端(Web、APP、小程序)的文檔服務平臺。在這個平臺,有兩個主要的角色,文檔發布者和文檔消費者。
- 發布者(publisher)會在這個平臺上不定期的上傳文檔內容。
- 消費者(consumer)會在這個平臺上通過搜索獲取他們需要的文檔材料。
我們根據這樣一個場景,來初步分析一下推薦業務如何開展。對于任意一個推薦業務,我們都可以先簡單抽象成3張寬表:用戶表、物料表、用戶行為表。
該場景的用戶表,是所有consumer的信息集合。物料表是publisher發布的所有物料的集合。用戶行為表是用戶在這個平臺上產生的所有行為。
我們通過上述場景來理解推薦系統架構。
3.1 存儲系統
存儲系統。存儲系統中飽含候選物品、用戶信息、特征和模型。
物品索引:在這個例子中,物品加入組件監視一組生成新物品的物品源(例如:發布者)。當新物品j產生時,物品加入組件提取物品特征,并將物品以及其特征放入物品索引,以便按特征快速檢索物品。
這么說比較抽象,具體一點就是說,比如我們首頁相關推薦用的物料庫,在2021年6月1日23點59分有物料更新,那么系統會監測到這個時間點有物料更新,并且對這些更新的物料進行特征抽取,計算完畢后會將這些特征存儲在我們的存儲系統中。
用戶數據存儲區:用戶特征存在于用戶數據存儲區中。該存儲區是一個鍵-值存儲區,支持通過給定一個鍵(比如:用戶ID)快速檢索出值(比如:用戶特征)。
模型存儲區:離線學習組件按一定周期更新模型。
3.2 離線學習
給定用戶和物品的特征,以及用戶的行為數據,也就是三表(用戶表、物料表、用戶行為表),離線訓練模型。因為離線學習很容易耗費好幾個小時,因此在西藍花資訊文檔這個case中,我們每天執行一次離線學習。
3.3 在線學習
實時更新模型,暫不展開。
3.4 推薦服務
每當客戶發一個request,經過網關、后臺,返回對應結果。
數據流部分下一篇講哦。
如果這篇文章對你有幫助,并且有興趣看接下來的更新~
#專欄作家#
一顆西蘭花,人人都是產品經理專欄作家。關注AI產業與寫作工具,擅長數據分析,產品研發管理。
本文原創發布于人人都是產品經理。未經許可,禁止轉載
題圖來自Unsplash,基于CC0協議