
編輯導語:推薦系統中包含著許多模塊,數據流是其中的一個重要模塊。在上篇文章里,作者闡述了推薦策略產品中的系統框架及模塊演進;本篇文章里,作者總結了推薦系統框架中的數據流模塊,讓我們一起來看一下。

在本章節,我們來了解推薦系統框架的數據流。
一、概括
為什么要了解數據流?
對于一款非常復雜的產品,比如像推薦系統這塊由多個模塊組成的產品,只有了解了其數據流,才能知道這個系統是如何運作的。
對于產品經理自身而言,只有了解了整體數據流,才能增強自己對復雜產品設計的把控能力。
二、推薦系統數據流
1. 背景Brief
要了解推薦系統的數據流,首先需要知道,對于一個推薦系統,主要的數據模塊。可以將其抽象成3個模塊:用戶數據、物料數據、用戶行為。
2. 推薦系統目標
對于一個推薦系統,它的目標是什么?通過兩個case來了解。
1)Case 1:資訊場景
比如資訊場景業務目標是點擊率。點擊率的計算邏輯 = click / show。
那為了提升點擊率,我們需要哪些數據實現目標?
- 靜態數據:用戶表、物料表。
- 用戶行為數據:用戶行為數據。
聚焦到用戶行為數據,如何定義哪些是正樣本、哪些是負樣本。
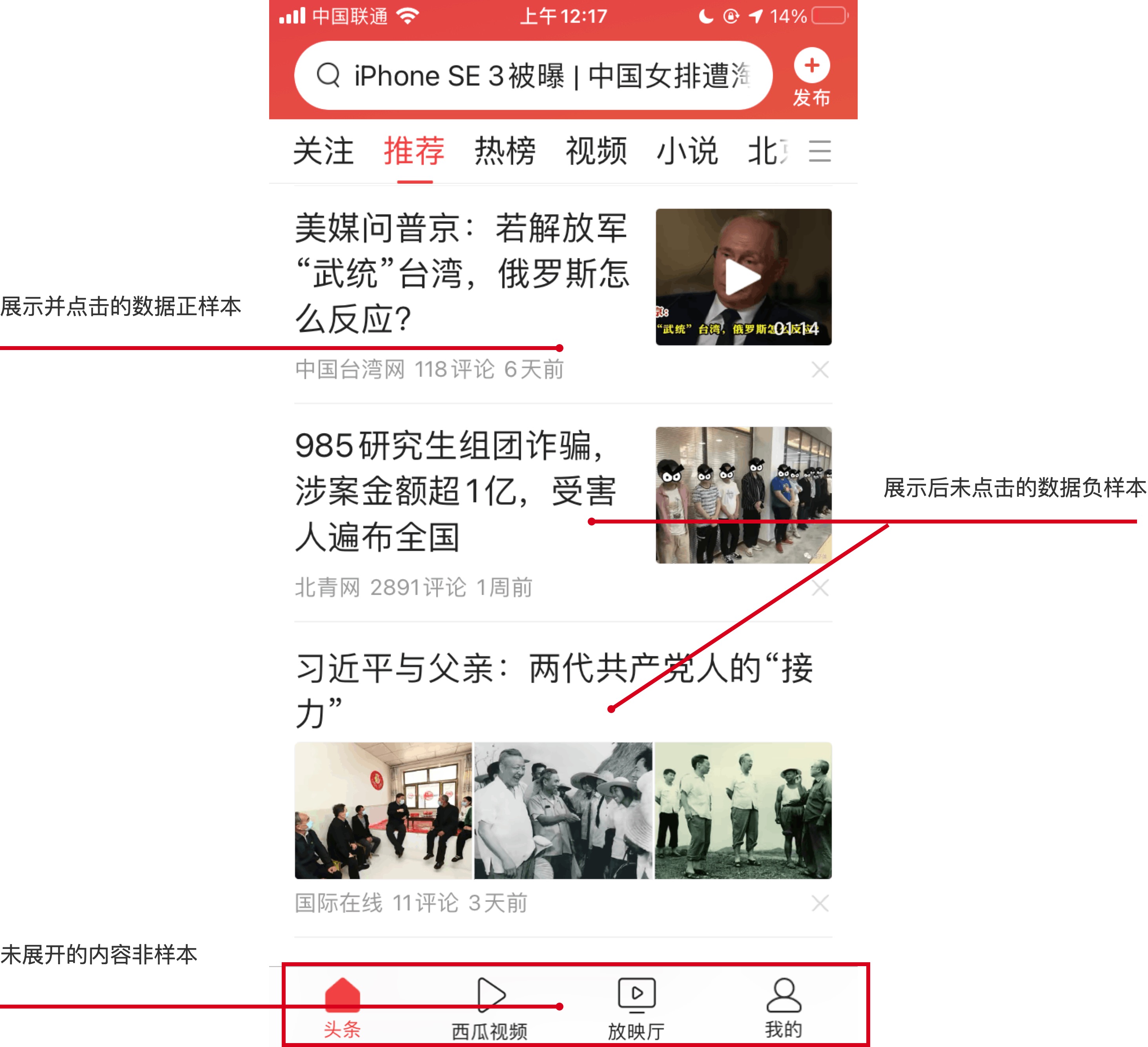
需要注意的是,在行為數據定義時候(樣本定義時候),經常出現的幾個show虛報的問題:
- 推薦結果即show。推薦結果即show的意思是,比如一個相關推薦場景,后臺服務器一次給出的預測結果是10條數據,客戶端只展現了4條。為了圖方便,客戶的上報show的邏輯是將所有的返回推薦結果都上報為show。
- 加載即show。在信息流場景,往往需要預加載。但是很多預加載的item,實際上尚未被展示。客戶的埋點邏輯是加載即上報show,因此會導致show虛高。
- 信息流上下滑動。在信息流場景,還經常出現的一個問題是,用戶經常上下刷動,所以同一物料會有多次曝光,建議上報時候做去重設置。
2)Case 2:小視頻場景
比如小視頻場景,建模目標是完播率,即視頻的播放時長/視頻的總時長。
3. 推薦系統如何實現業務目標
將推薦系統實現業務目標拆分成兩條數據流來理解,在線數據流和離線數據流。
1)在線數據流
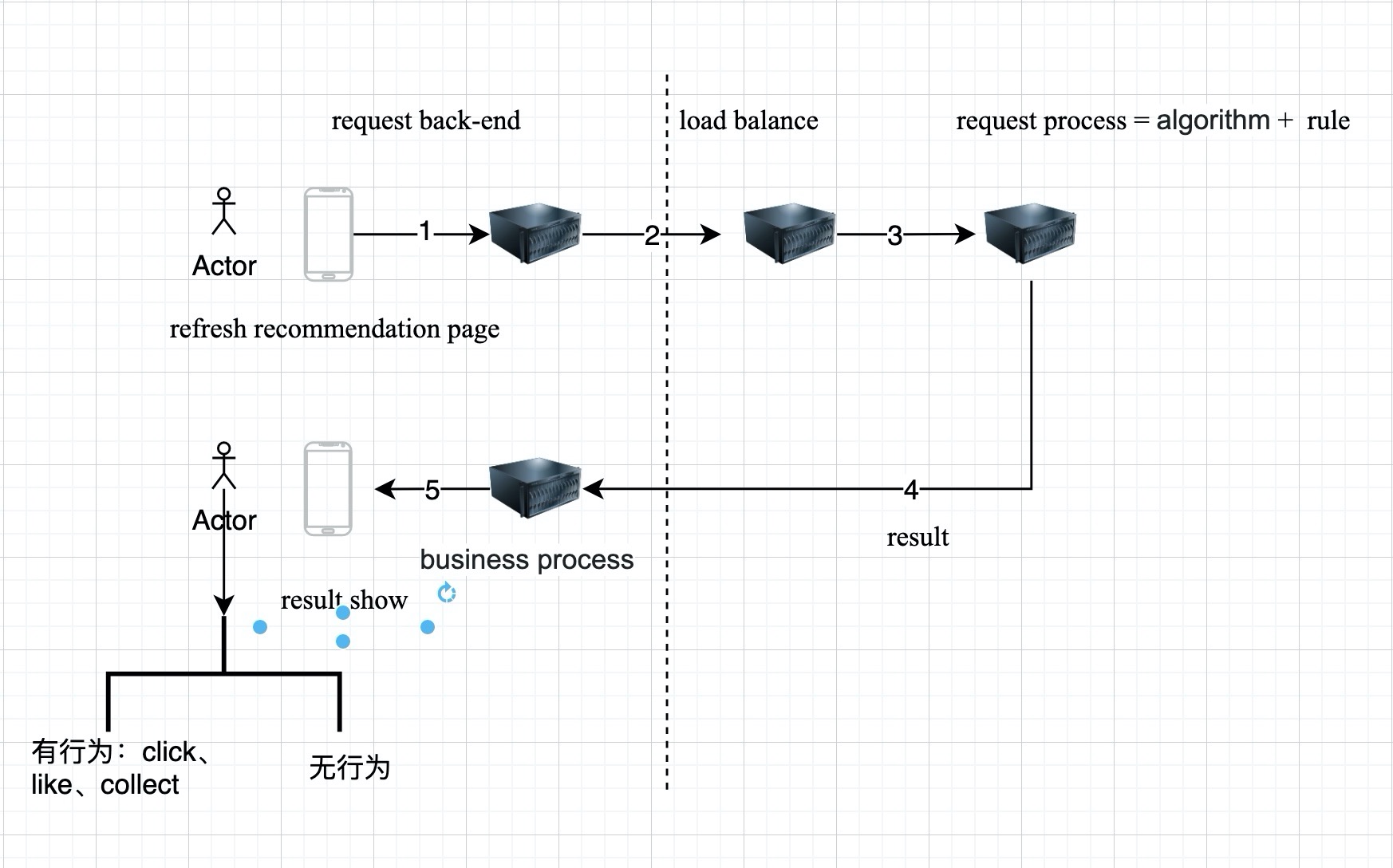
在線數據流是指一個請求進入到推薦系統到給出預估結果的流程,參考下述示例圖。
接著進一步了解在線數據流。
用戶來到APP,打開APP,這個時候前端會像服務器后端發送請求,接著服務器后端會像推薦系統(SaaS服務)發送請求。
推薦服務接受到這個請求,會先進行load balance,接著后端處理,在后端處理分為算法和規則,算法即召回和排序,規則即rerank。
根據2.2的描述,我們知道,對于一個推薦系統來說,都有其特定的目標,當我們完成目標確認后,比如提升點擊率或者完播率。
接著就可以開始建模了。假設模型已經ready。來看一下推薦系統的在線流程~
- 召回(Recall):召回的作用是從整個物料庫中,通過某一種/多種策略,快速召回一小批物料,供后續模型打分使用。
- 排序(Rank):排序是將前一個階段召回的物料進行模型排序。
- 重排(Rerank)
重排是什么?
重排是基于排序環節的打分結果,對上述結果再次進行排序。
為什么需要重排?
在上一個環節,排序做的事本質上是預測用戶對物品該興趣的概率,考慮的只是物品與用戶之間的關系,但是忽略掉了物品之間的相關性。
如何理解呢?分享一個極端的case,小紅最近酷愛刷電影剪輯類小視頻,模型學習的話,很可能學出來最后給用戶推薦的都是同一個publisher的10條item。
這樣肯定是不行的,試想,如果你正在刷抖音,連續10條都給你推薦同一個博主的內容,這個體驗能好嗎?所以需要rerank。
重排環節一般會做什么?
重排階段是個策略出沒之地,就是集中了各種業務和技術策略。比如為了更好的推薦體驗,這里會加入去除重復、結果打散增加推薦結果的多樣性、強插某種類型的推薦結果等等不同類型的策略。
2)離線
什么是離線數據流呢?模型訓練以及模型的更新都是離線數據流完成的事。
離線模型的訓練以及模型的更新,涉及到多個數據模塊的配合,包括用戶畫像、物料畫像、行為日志,離線數據流,我們下章節見~
#專欄作家#
一顆西蘭花,人人都是產品經理專欄作家。關注AI產業與寫作工具,擅長數據分析,產品研發管理。
本文原創發布于人人都是產品經理。未經許可,禁止轉載
題圖來自Unsplash,基于CC0協議